
2023-02-08 , 7435 , 104 , 95
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-9
代码预训练增强LLM推理能力
以上是目前利用Prompt激发LLM模型推理能力的三种主流做法,而关于LLM的推理能力,目前还观察到一个有趣且费解的现象:除了文本外,如果能够加入程序代码一起参与模型预训练,则能大幅提升LLM模型的推理能力。这个结论从不少论文的实验部分都可以得出(可以参考:AUTOMATIC CHAIN OF THOUGHT PROMPTING IN LARGE LANGUAGE MODELS/Challenging BIG-Bench tasks and whether chain-of-thought can solve them等论文的实验部分)。
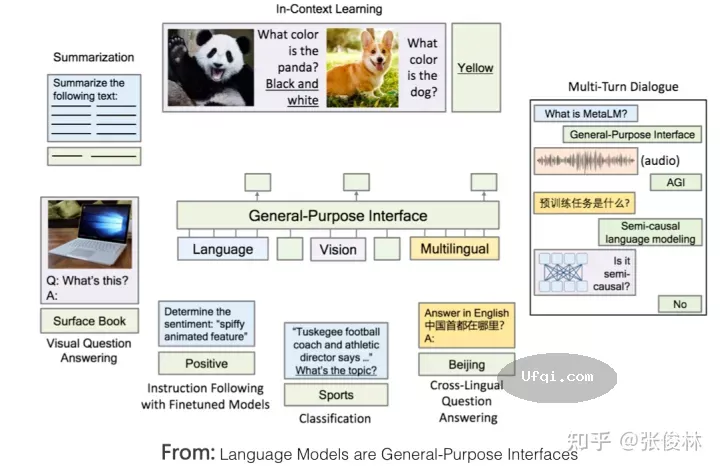
上图给出了一份实验数据,来自于论文 “On the Advance of Making Language Models Better Reasoners”,其中GPT3 davinci就是标准的GPT 3模型,基于纯文本训练;code-davinci-002(OpenAI内部称为Codex)是同时在Code和NLP数据上训练的模型。如果比较两者效果,可以看出,不论采用具体哪种推理方法,仅仅是从纯文本预训练模型切换到文本和Code混合预训练模型,在几乎所有测试数据集合上,模型推理能力都得到了巨大的效果提升,比如我们以“Self Consistency”方法为例,在大多数据集合上的性能提升,都直接超过了20到50个百分点,这是很恐怖的性能提升,而其实在具体推理模型层面,我们什么也没做,仅仅是预训练的时候除了文本,额外加入了程序代码而已。

除了这个现象,从上图数据中,我们还可以得出其它一些结论,比如GPT 3这种纯文本预训练模型,其实是具备相当程度的推理能力的,除了在GSM8K这种数学推理上效果比较差外,其它推理数据数据集合表现也还可以,前提你需要采用合适的方法,来激发出它本身就具备的这种能力;再比如,text-davinci-002,也就是在code-davinci-002基础上加入instruct fine-tuning后的模型(就是加入InstructGPT或ChatGPT模型的第一步),其推理能力要弱于Codex,但是有其它研究表明它在自然语言处理任务又要强于Codex。而这貌似说明了,加入instruct fine-tuning,会损害LLM模型的推理能力,但是会在一定程度上提升自然语言理解能力。
而这些结论其实都是很有意思的,也能启发后续进一步的思考和探索。
那么,一个自然的疑问是:为何预训练模型可以从代码的预训练中获得额外的推理能力?确切原因目前未知,值得深入探索。我猜测可能是因为原始版本的Codex(只使用代码训练,可参考文献:Evaluating Large Language Models Trained on Code)的代码训练是从文本生成代码,而且代码中往往包含很多文本注释,本质上这类似于预训练模型做了<文本,Code>两种数据的多模态对齐工作。
而数据中必然包含相当比例的数学或逻辑问题的代码、描述和注释,很明显这些数学类或逻辑推理类的数据,对于解决下游数学推理问题是有帮助的,我猜大概率原因在此。
关于LLM推理能力的思考
上面介绍了LLM推理的主流技术思路和现有的一些结论,接下来谈谈我对LLM模型推理技术的思考,以下内容纯个人推断,没有太多证据,还请谨慎参考。我的判断是:虽然最近一年来,关于激发LLM的推理能力,这方面的技术进展很快,也取得了很大的技术进步,但是总体感觉是,我们可能走在正确的方向上,但是距离接触到真正的问题本质还有一段距离,对此要有更深入的思考和探索。
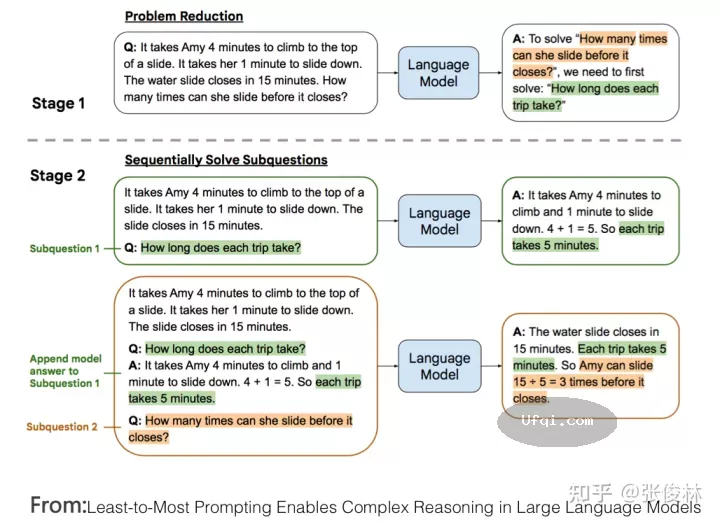
首先,我比较赞同上述分治算法的主体思路,对于复杂的推理问题,我们应该把它拆解成若干简单的子问题,因为子问题对于LLM来说回答正确的概率就大很多,让LLM一一回答子问题后,再逐步推导出最终答案。受到 “Least-to-most prompting”技术的启发,如果进一步思考,我觉得LLM推理本质上很可能会是如下两种可能的其中之一:不断和LLM进行交互的图上推理问题,抑或是不断和LLM进行交互的程序流程图执行问题。
先说图上推理问题,如上图所示,假设我们有办法能够把复杂问题拆解成由子问题或者子步骤构成的图结构,图中的节点是子问题或者子步骤,图中的边代表了子问题之间的依赖关系,就是说只有回答好子问题A,才能回答子问题B,而且图中大概率存在循环结构,就是反复做某几个子步骤。假设我们能够得到上述的子问题拆解图,那么可以根据依赖关系,引导LLM一步一步按照图结构,回答必须首先回答的子问题,直到推导出最终答案。
UfqiLong
再说程序流程图问题,参考上图,假设我们有办法把复杂问题拆解成子问题或子步骤,并产生一个由子步骤构成的类似程序流程图的结构,在这个结构里,有些步骤会反复执行多次(循环结构),有些步骤的执行需要进行条件判断(条件分支)。总而言之,在执行每个子步骤的时候和LLM进行交互,得到子步骤的答案,然后按照流程不断执行,直到输出最终答案。类似这种模式。假设这个思路大致正确的话,也许可以从这个角度来解释为何加入代码会增强预训练模型的推理能力:大概率因为<文本,代码>的多模态预训练模型,在模型内部是通过类似这种隐含的程序流程图作为两个模态的桥梁,将两者联系起来的,即由文本描述到隐含的流程图,再映射到由流程图产生具体的代码。也就是说,这种多模态预训练,可以增强LLM模型从文本构建出隐含的流程图并按照流程图执行的能力,也就是加强了它的推理能力。
当然,上述思路最大的问题是,我们如何根据文本描述的问题,能够靠LLM模型,或者其它模型,得到图结构或者流程图结构?这个可能是其中的难点。一种可能的思路就类似继续增强文本和更高质量的代码预训练,走隐式学习内部隐含结构的方法。
而目前的CoT技术,如果套到上述思路来思考的话,可以这么理解:标准CoT,其实就是靠自然语言文本来描述图结构或者程序流程图的;而 “Least-to-most prompting”技术,则是试图根据最后一个图节点,靠倒推来试图推导出其中的图结构,但是很明显,目前的方法限制了它倒推的深度,也就是说它只能推导出非常简单的图结构,这正是限制它能力的所在。

🔗 连载目录
8. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-2
9. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-3
 10. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4
10. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4
11. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-5
12. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-6
13. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-7
 14. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-8
14. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-8
🔴 15. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-9
16. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-10
17. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11
19. 美国微软内部人士谈谈OpenAi的强人工智能ChatGPT
20. 美国OpenAi公司的人工智能聊天机器人ChatGPT能取代多少程序员?
21. 美国OpenAi公司的人工智能聊天机器人ChatGPT能取代多少程序员?-2
22. 人工智能AI真正的令人恐怖之处
2324. 百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
🤖 智能推荐
理解计算:从根号2到AlphaGo -21: 第8季 深度学习发展简史-2
理解计算:从根号2到AlphaGo -23: 第8季 深度学习发展简史-4
理解计算:从根号2到AlphaGo -20: 第8季 深度学习发展简史
理解计算:从根号2到AlphaGo -22: 第8季 深度学习发展简史-3
理解计算:从根号2到AlphaGo -15: 第6季 多维的浪漫:统计学习理论与支持向量机-3
理解计算:从根号2到AlphaGo -13:第6季 多维的浪漫:统计学习理论与支持向量机
有关人工智能Artificial Intelligence AI的若干认识问题
🔥 相关精选
Amazon CEO Jassy亚马逊电商总裁贾西年度致股东的信-2022年-2
JavaScript服务器端编程环境NodeJs知识体系和原理浅析-6
大模型物种进化图转疯了:8位华人打造,一眼看懂“界门纲目” 21
 研究发现AI生成文本水印能被轻易擦掉,水印伪造成功率竟达80%左右 12
研究发现AI生成文本水印能被轻易擦掉,水印伪造成功率竟达80%左右 12
