2023-02-08 , 7436 , 104 , 104
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-10
未来之路:LLM研究趋势及值得研究的重点方向
这里列出一些我个人认为比较重要的LLM研究领域,或值得深入探索的研究方向。
探索LLM模型的规模天花板
尽管继续推大LLM模型的规模,这事看似没有技术含量,但是其实这个事情异常重要。我个人判断,自从Bert出现以来,到GPT 3,再到ChatGPT,大概率这些给人印象深刻的关键技术突破,核心贡献都来自于LLM模型规模的增长,而非某项具体技术。说不定,揭开AGI真正的钥匙就是:超大规模及足够多样性的数据、超大规模的模型,以及充分的训练过程。
再者,做超大规模的LLM模型,对技术团队的工程实现能力要求是非常高的,也不能认为这事情缺乏技术含量。
那么继续推大LLM模型规模,有什么研究意义呢?我觉得有两方面的价值。首先,如上所述,我们已知,对于知识密集型的任务,随着模型规模越大,各种任务的效果会越来越好;
而对很多推理类型的有难度的任务,加上CoT Prompting后,其效果也呈现出遵循Scaling law的趋向。那么,很自然的一个问题就是:对于这些任务,LLM的规模效应,能将这些任务解决到何种程度?这是包括我在内,很多人关心的问题。其次,考虑到LLM具备的神奇的 “涌现能力”,如果我们继续增加模型规模,它会解锁哪些让我们意想不到的新能力呢?这也是很有意思的问题。考虑到以上两点,我们仍然需要不断增大模型规模,看看模型规模对解决各类任务的天花板在哪里。
当然,这种事情也就只能说说,对99.99%的从业者来说,是没有机会和能力做这个事情的。要做这个事情,对研究机构的财力及投入意愿、工程能力、技术热情,都有极高的要求,缺一不可。能做这事情的机构,粗估下来,国外不超过5家,国内不超过3家。
当然,考虑到成本问题,未来也许会出现 “股份制大模型”,就是有能力的几家机构合作,群策群力,一起来共建超级大模型的现象。
增强LLM的复杂推理能力

正如之前对LLM推理能力的叙述,尽管LLM在最近一年推理能力得到了很大的提升,但是很多研究(参考:Limitations of Language Models in Arithmetic and Symbolic Induction/Large Language Models Still Can’t Plan)表明,目前LLM能够解决得比较好的推理问题,往往都相对简单,LLM的复杂推理能力仍然薄弱,比如即使是简单的字符拷贝推理或者加减乘除运算,当字符串或者数字非常长的时候,LLM推理能力会极速下降,再比如行为规划能力等复杂推理能力很弱。总而言之,加强LLM的复杂推理能力,应该是LLM未来研究中最重要的环节之一。
前文有述,加入代码加入预训练,这是一种直接增强LLM推理能力的方向。这个方向目前研究尚显不足,更像是实践经验的总结,探索背后的原理,并进而引入更多类型除代码外的新型数据来增强LLM的推理能力,这可能是更本质提升推理能力的方向。
LLM纳入NLP之外更多其它研究领域
目前的ChatGPT擅长NLP和Code任务,作为通向AGI的重要种子选手,将图像、视频、音频等图像与多模态集成进入LLM,乃至AI for Science、机器人控制等更多、差异化更明显的其它领域逐步纳入LLM,是LLM通往AGI的必经之路。而这个方向才刚刚开始,因此具备很高的研究价值。
更易用的人和LLM的交互接口
如前所述,ChatGPT的最大技术贡献即在此。但是很明显,目前的技术并不完美,肯定还有很多命令LLM理解不了。所以,沿着这个方向,寻找更好的技术,来让人类使用自己习惯的命令表达方式,而LLM又能听懂,这是个新的,且非常有前景的技术方向。
建设高难度的综合任务评测数据集
好的评测数据集,是引导技术不断进步的基石。随着LLM模型逐步增大,任务效果快速提升,导致很多标准测试集快速过时。也就是说,这些数据集合相对现有技术来说,太容易了,在没有难度的测试集合下,我们不知道目前技术的缺陷和盲点在哪里。所以构建高难度的测试集合,是促进LLM技术进步的关键所在。
目前行业应出现了一些新的测试集,有代表性的包括BIGBench、OPT-IML等。这些测试集合体现出一些特性,比如相对LLM现有技术具备一定的难度、综合了各种各样多种类型的任务等。
受到ChatGPT的启发,我觉得除此外应纳入另一考虑因素:体现真实用户需求。就是说,这些任务的表述由用户真实发起,这种方式构建出来的LLM模型,才能解决用户实际需求。
除此外,相信LLM会快速将能力溢出到NLP之外的领域,而如何融入更多其它领域的评测数据,也是需要提前去考虑。
高质量数据工程
对于预训练模型来说,数据是其根本,预训练过程可以理解为从数据中吸取其中所包含知识的过程。因此,我们需要进一步加强对高质量数据的挖掘、收集及清洗等工作。
关于数据,需要考虑两个方面:数据的质量和数量。而根据T5的对比实验,我们可以得出结论:在数量和质量两个因素里,质量优先,正确的道路应该是在保证数据质量的前提下,再去增大数据规模。
数据质量,包括数据的信息含量以及数据的多样性等多个衡量标准,比如Wiki明显就属于世界知识密度极高的高质量数据,这是从信息含量来说的;而增加数据类型的多样性,无疑是激发LLM各种新能力的根本,比如加入问答网站的数据,对于LLM的QA能力提升是有直接帮助的。多样化的数据赋予了LLM更好解决更多不同类型任务的能力,所以,这可能是数据质量里最关键的标准。
关于数据数量,原则上互联网上公开发布的数据都可以纳入LLM模型的预训练过程。那么,它的极限在哪里? “Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning” 对此进行了估算,结论是到2026年左右,高质量的NLP数据将会用光,低质量NLP数据会在2030到2050年用光,而低质量图像数据会在2030到2060年用光。
而这意味着:要么到时我们有新类型的数据源,要么我们必须增加LLM模型对数据的利用效率。否则,目前这种数据驱动的模型优化方式将会停止进步,或者收益减少。
UfqiLong
超大LLM模型Transformer的稀疏化
目前规模最大的LLM中,有相当比例的模型采取了稀疏(Sparse)结构,比如GPT 3、PaLM、GLaM等,GPT 4大概率也会走稀疏模型路线。之所以采用Sparse 化的模型,主要好处是它可以极大减少LLM的训练时间和在线推理时间。Switch Transformer论文里指出:在相同算力预算的前提下,使用稀疏化Transformer,相对Dense Transformer,LLM模型的训练速度可以提升4倍到7倍。
为何Sparse模型可以加快训练和推理时间呢?这是因为尽管模型参数巨大,但是对于某个训练实例,Sparse模型通过路由机制,只使用整个参数中的一小部分,参与训练和推理的活跃参数量比较少,所以速度快。
我认为未来超大的LLM模型大概率会收敛到稀疏模型。主要有两个原因:一方面,现有研究表明(参考:Large Models are Parsimonious Learners: Activation Sparsity in Trained Transformers),标准的Dense Transformer在训练和推理时,它本身也是稀疏激活的,就是说只有部分参数会被激活,大部分参数没有参与训练和推理过程。既然这样,我们不如直接迁移到稀疏模型;另外,毫无疑问LLM模型的规模会继续推大,而高昂的训练成本是妨碍其进一步扩大模型的重要阻力,使用稀疏模型可以极大降低超大模型的训练成本,所以随着模型规模越大,稀疏模型带来的收益越明显。考虑到这两个方面,大概率未来更大的LLM模型会采用稀疏模型方案。
那为何目前其它大规模模型不走稀疏模型的路线呢?因为Sparse模型存在训练不稳定、容易过拟合等问题,不太容易训练好。所以,如何修正稀疏模型面临的问题,设计出更容易训练的稀疏模型,是很重要的未来研究方向。

🔗 连载目录
9. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-3
 10. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4
10. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4
11. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-5
12. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-6
13. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-7
 14. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-8
14. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-8
15. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-9
🔴 16. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-10
17. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11
19. 美国微软内部人士谈谈OpenAi的强人工智能ChatGPT
20. 美国OpenAi公司的人工智能聊天机器人ChatGPT能取代多少程序员?
21. 美国OpenAi公司的人工智能聊天机器人ChatGPT能取代多少程序员?-2
22. 人工智能AI真正的令人恐怖之处
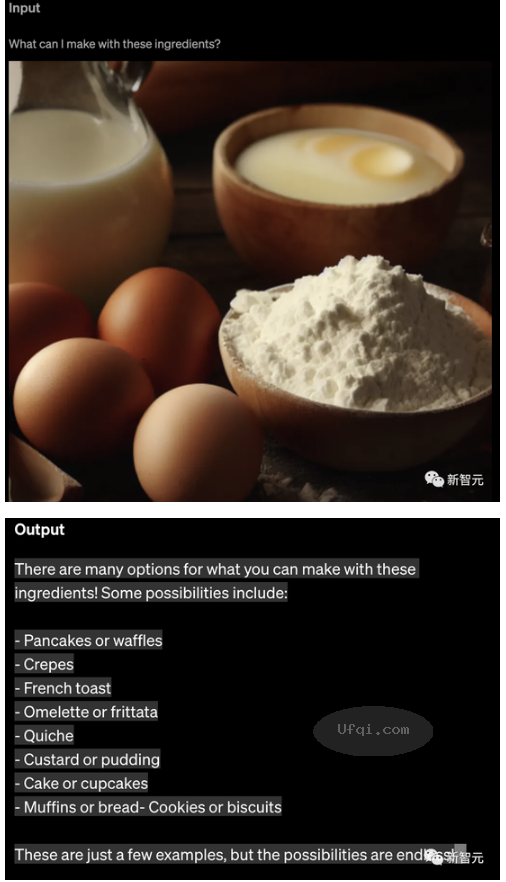 23. 美国OpenAI的ChatGPT-4发布:多模态图文混合交互
23. 美国OpenAI的ChatGPT-4发布:多模态图文混合交互
24. 百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
🤖 智能推荐
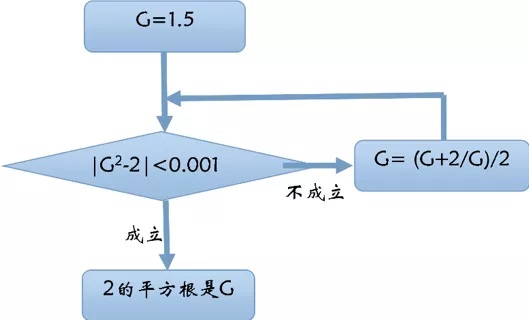
理解计算:从根号2到AlphaGo -21: 第8季 深度学习发展简史-2
 聪明的投资者 The intelligent investor-27:第十二章:股票收益和价格的变动模式
聪明的投资者 The intelligent investor-27:第十二章:股票收益和价格的变动模式
理解计算:从根号2到AlphaGo -23: 第8季 深度学习发展简史-4
理解计算:从根号2到AlphaGo -20: 第8季 深度学习发展简史
理解计算:从根号2到AlphaGo -22: 第8季 深度学习发展简史-3
理解计算:从根号2到AlphaGo -15: 第6季 多维的浪漫:统计学习理论与支持向量机-3
理解计算:从根号2到AlphaGo -13:第6季 多维的浪漫:统计学习理论与支持向量机
🔥 相关精选
理解计算:从根号2到AlphaGo -14: 第6季 多维的浪漫:统计学习理论与支持向量机-2
有关人工智能Artificial Intelligence AI的若干认识问题