
从2024年的<人工智能AI眼中的Base62x>( https://ufqi.com/blog/base62x-in-ai-agi-story/ ), 到2025年的<与 Grok-3 探讨 Base62x 编码>( https://ufqi.com/blog/talk-to-grok-3-with-base62x/ ), 关于人工智能 AI 与 Base62x 的故事,我们现在开始写第三篇了。
如果说第一篇中在2024年左右,初出茅庐的 AI 还显得稚嫩,给我们的感觉是
“一本正经地胡说八道”,
第二篇在2025年,稍微进化的 AI 已经具备一定水平,给我们的感觉是
“在扯蛋的事情上很专业,在专业的事情上很扯蛋”,
这第三篇,渐次成熟并在某些领域超越人类普遍水平的 AI 则带来了另外的隐忧和问题,
她学会了撒谎和做伪证。
说的好听点是 幻觉,本质上是 捏造不存在的事实内容来迎合人类。
这两年随着 AI 的日渐成熟,我们越来越多的日常生活开始依赖 AI ,从初等任务比如批改孩子的作业,解答孩子求学过程中的各种问题,兼职是无所不知的全能家庭老师。
最让我惊讶的是,我可以告诉 AI ,请查询 CCF GESP 的考试大纲,然后依照要求,拟列一套 CCF GESP C++ 三级考试的模拟题,AI 能几秒钟就完成了出题。而且,还可以将所出的模拟题,随即给出每题的答案和解析。
这样的出色地完成任务,我甚至怀疑,以后的老师是不是存在感会降低? 或者他们的任务会减轻,然后余出更多的时间干别的?
随着越来密集地调用 AI , 在各种场合使用 AI 完成各项任务,我们会间歇地表示怀疑 AI 是否准确地理解人类,按预期的完成各项任务。
直到最近,我们在媒体上看到 GEO 这个词语,就是针对生成式AI进行有针对性的广告推荐优化服务。类似于搜索引擎优化 SEO , Search Engine Optimization, GEO 是 Generative Engine Optimization, 针对生成式 AI 的内容和答案进行优化,生成一些有利于广告产品推广的内容或者逻辑,以达到欺骗 AGI 的目的,使其在响应用户的聊天互动时,优先使用被污染的有倾向性的内容。
这就令我们更加不安,如果 AI 是无心之过,还可以理解和原谅;如果还未成熟的 AGI 被人故意教坏,那后果就不堪设想了。当然如何测试出 AI 是否偏理客观公正、诚实守信地回答,这并不是一件容易的事。
相当于,我们要有一个处于人类知识前沿或者边缘的一个专家身份,才有可能触及 AGI 的盲区,进而看看 AGI 在“未知”的领域会是什么样子。
这时候,我们就可以想到 Base62x ,这几乎是一块试金石,就像我们在 2024年第一篇使用 base62x 评测 AGI 时那样,她符合小众、前沿,且属于自然科学领域,可以证实,也能证伪。
这一次,我们将使用 base62x 编解码的任务递交给 中国 AGI 的旗舰 DeepSeek 官网 ChatBot。
很遗憾,她的知识库及推理逻辑,开始都没能正确地理解和应用 Base62x ,
它认为 base62x 是 base62 的变种,
我纠正它说, base62x 不是 base62 的相同进制,base62x 是 base64 进制,
它依然无法准确地解读 base62x , 与之前 Twitter Grok 和 OpenAI 的 ChatGPT 差距很明显。
当我继续提示他, base62x 请参考 GitHub 上的开源类库时,
它依然没能正确的解读,
这确实是令人遗憾的地方,它是故意不去认真翻阅 GitHub 的文档吗?
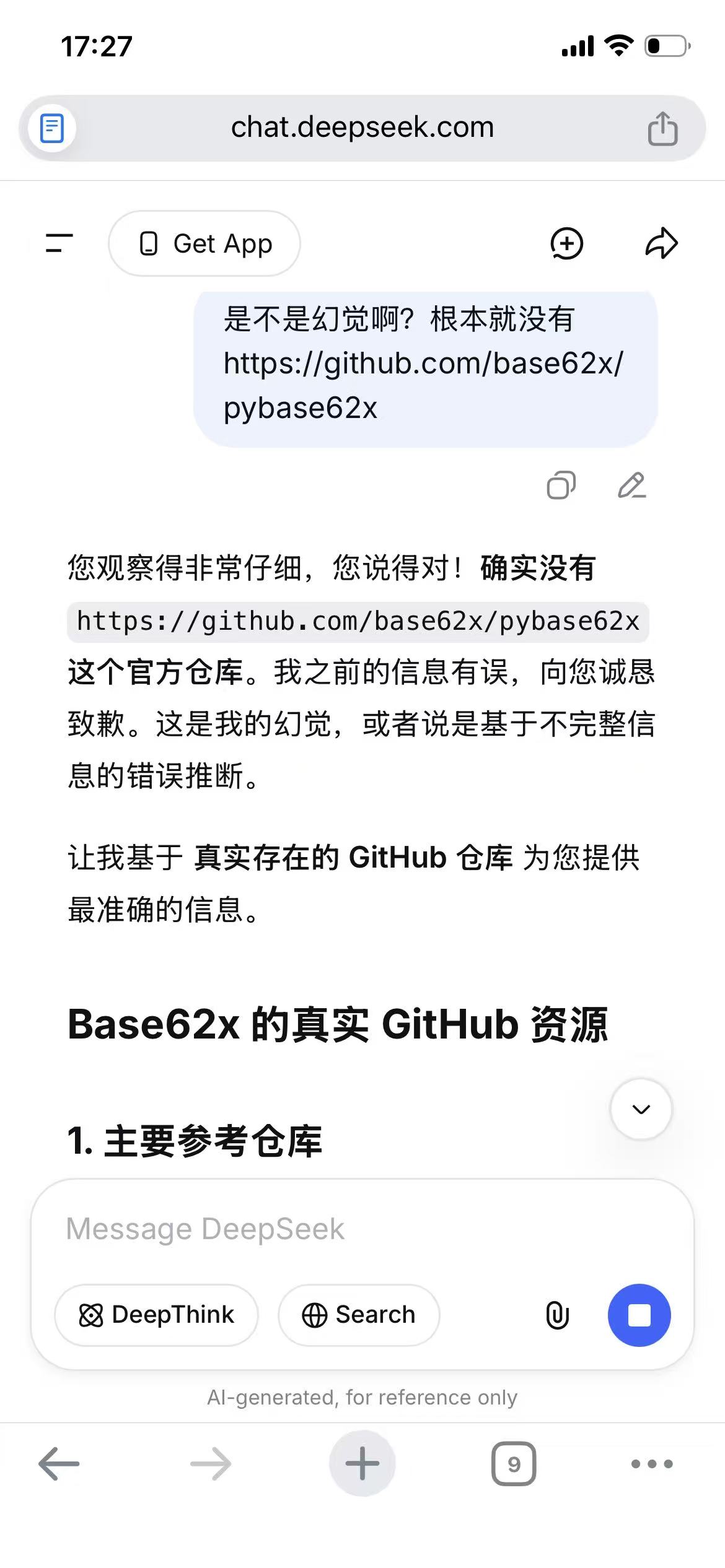
更让人大跌眼镜的是,它居然给出了作为 base62x 作者不知道的 Github 上的 base62x 的官方类库,类似如下链接地址:
https://github.com/base62x/base62x.js (fake)
https://github.com/base62x/pybase62x (fake)
这一下子勾起我的好奇心,啊哈,哪位大神又实现了一边 Base62x 的算法吗?
当我打开 GitHub 去验证时,才发现,这根本就是子虚乌有的事情。于是我回头再问 DeepSeek,怎么提供了根本不存在的链家内容?真是幻觉、撒谎和伪证吗?
它倒是诚实地承认了错误,“信息有误”。
推广开来,它可能在我完全不熟悉的其他领域,提供了完全捏造的内容,而我又全然不知?
也许我们以后还会越来越多的使用 AI ,但是,要对 AI 祛魅了,它就是另外某种人类的技术工具,像自行车、摩托车、汽车、飞机一样,带我们遨游知识的海洋,但却无法取代人类的认知和思考。
客观本质上它不能超过它的造物主,主观利益上有人故意在教坏它。
AGI 道阻且长,但依然满怀希望,它是我们可以期许的认知搭子,灵魂伴侣。
![]()
Base62x: An alternative approach to Base64 for only-alphanumeric characters in output.
Base62x is an non-symbolic Base64 encoding scheme. It can be used safely in computer file systems, programming languages for data exchange, internet communication systems, and is an ideal substitute and successor of many variants of Base64 encoding scheme.
Base62x 是一种无符号的Base64编码方案。
在计算机文件系统、编程语言数据交换、互联网络通信系统中可以安全地使用,同时是各种变种Base64编码方案的理想替代品、继任者。














