-
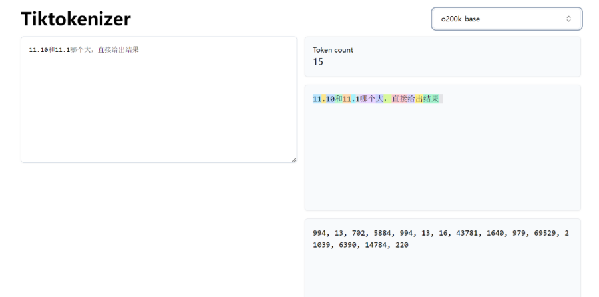
07-25 15:20...“一道小学生难度的数学题竟然难倒了一众海内外AI大模型。”关于大模型对数字小数部分识别混淆的问题,业内早有关注,其本质原因并非是在数学计算方面遇到了困难,而是因“分词器”拆解错误和大模型技术架构使然,导致在审题时陷入了误区。除了数学类问题之外,包括在复杂字母图形的识别,复杂语句的梳理等场景下也都存在类似逻辑推理能力缺陷... 6
-
07-19 11:20...由于MistralNeMo依赖于标准架构,因此易于使用,可在任何使用Mistral7B的系统中成为替代品。下表比较了MistralNeMo基本模型与两个最新的开源预训练模型(Gemma29B和Llama38B)的准确性。(严格来讲,这个对比不太公平,毕竟MistralNeMo的参数量比另外两个都要大不少)表1:Mist... 1
-
06-04 20:40...该模型被指抄袭面壁智能发布的MiniCPMLlama3-V2.5,且声浪越来越大。面壁智能是一家“清华系”人工智能大模型创业公司,成立于2022年8月,今年4月刚刚宣布完成新一轮数亿元融资。面壁智能自研了百亿参数预训练语言大模型CPM,MiniCPM是其端侧模型,也被称为“小钢炮”。今年5月20日,面壁智能推出并开源M... 1
-
06-03 20:00...面壁智能联合创始人兼CEO李大海在朋友圈回应说“深表遗憾”,这也是一种“受到国际团队认可的方式”,并呼吁大家共建开放、合作、有信任的社区环境。一、网友细数五大证据,作者删库跑路、不打自招Llama3-V的模型代码与MiniCPM-Llama3-V2.5高度相似,同时其项目页面没有出现任何与MiniCPM-Llama3-... 15
-
05-19 19:40...甚至还有人称,在GPT-4o诞生之后发布的非常扎实的研究,OOS将迎头赶上。不过,目前Chameleon模型支持生成的模态,主要是图像文本。缺少了GPT-4o中的语音能力。网友称,然后只需添加另一种模态(音频),扩大训练数据集,「烹饪」一段时间,我们就会得到GPT-4o...?Meta的产品管理总监称,「我非常自豪能够... 10
-
02-14 04:00...2、模型架构调优:模型的深度、宽度对小语言模型效果极大。同参数量下,较深的模型往往效果更好,但推理效率更低。3、参数继承:继承大模型参数作为初始值可以提升模型效果并加速收敛。在挑选参数时,首尾层比中间层更重要,每层内的有效参数可以通过可学mask得到。4、多轮训练:多轮训练被验证对训小模型有效。上一轮训练记录的loss... 2
-

-
-
-
本页Url:
-
2025-03-01-06:16 GMT . 添加到桌面浏览更方便.
-

