
自然域名NatureDNS
NatureDNS是一种以自然语言为域名表达形式,通过将自然语言编码后的字符串与IP数字地址建立对应关系,实现网络域名寻址的技术系统。它采用通过语义本身来隐式地定义域,使用符合本地语言语法的词组或者句子的表达方式来定位网络资源。
NatureDNS域名由连续的实义字符组成,定义连字符“-”(hyphen)作为下一级子域的开始,或者称之为NatureDNS的根域 (“-”) 。NatureDNS的域名必须以连字符开始,而不能以连字符结尾,可以有多个子级域,其正则表达式为:
^-([^-]+)([-])([^-]+)$
连字符(hyphen)“-”在这里可以理解为“连接/前往(Connect/to)”某个主机/域,或者理解成就是一根可以连接任何网络的网线,与在电话号码前加“+”类似。
例子
下列NatureDNS域名表达式是合法的:
Table 1 NatureDNS域名样例
|
No.
|
NatureDNS域名
|
现行DNS域名
|
|
1
|
-Weibo
|
Weibo.com
|
|
2
|
-我爱你礼品网
|
www.iloveyou.com.cn
|
|
3
|
-新浪新闻
|
News.sina.com.cn
|
|
4
|
-人民网-财经
|
Finance.people.com.cn
|
|
5
|
-IBM-Redbooks-WEB
|
www.redbooks.ibm.com
|
下列NatureDNS域名是不合法的:
中国导航
-People-
其中两个以上连续的连字符会被等同视为一个。
域从大到小从左至右排列,域级之间使用连接符隔开,如:
-live-mail-bay146-bay146w
(by146w.bay146.mail.live.com)
上面的域名可以理解成从当前连接到live域的子域mail,再从mail的子域bay146中查找bay146w所代表的主机IP地址。
由于“-人民网财经”比“-人民网-财经”更符合人们使用习惯,因此前者可以单独注册一个独立域名以区别于后者“-财经”作为“-人民网”的子域。
注册与解析
NatureDNS与现行的DNS结构 [2] 相似,由4个部分构成:1)客户端解析器,2)本地DNS服务器,3)授权DNS服务器,4)根和顶级域DNS服务器。如Figure 6所示,其中的gTLD可能包含多层。
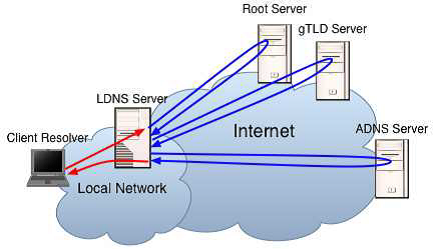
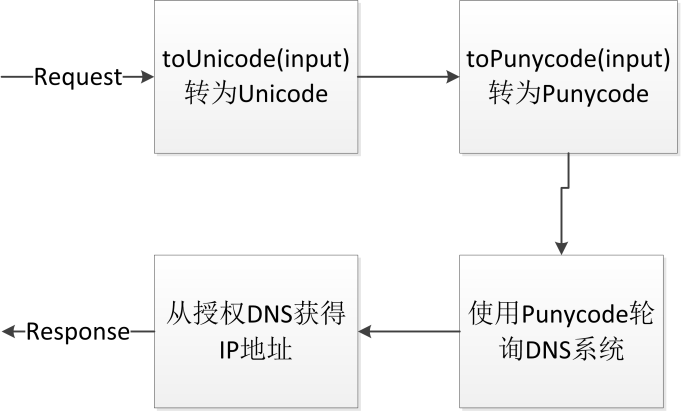
Figure 7 NatureDNS解析流程
NatureDNS解析过程除了在客户端做编码外,其余的与现有的DNS解析处理过程 [20] 一致,主要步骤如Figure 7所示。
NatureDNS域名的注册过程与现有DNS注册基本一致,除了在注册时,生成域名的Punycode并同时以Punycode为索引来存储和管理。
为正确显示和处理国际化语言,注册系统要支持UTF-8等国际化语言显示字符编码。
(2)
NatureDNS轮询系统
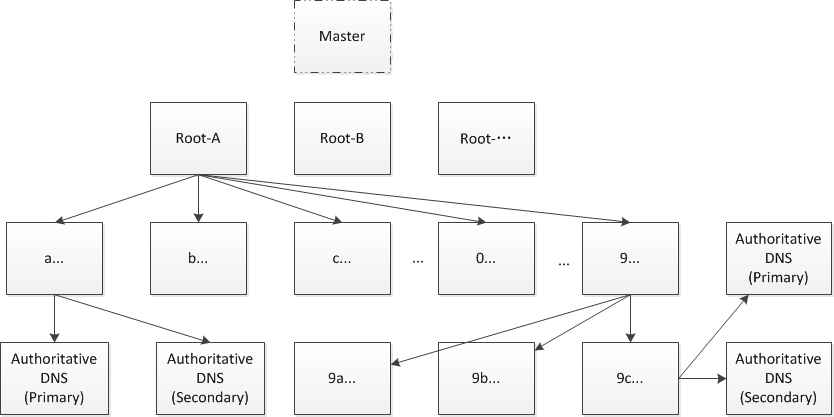
-自然域名递归层级
Figure 8 NatureDNS层级查询树
NatureDNS的轮询结构采用分层树状结构(如Figure 8)。在最顶层根服务器(Root-A, B, C等)。每个Root后面对应着一组顶级域查询服务器群,标记为“a…”的负责进一步的解析NatureDNS域名Punycode编码以字母a开头的顶级域名,以“b…”处理以字母b开头的Punycode编码的域名,循此直到z开头、0-9开头的顶级域名。
顶级数据表中,视所查询域名的情况,如果存在以连字符连接的二级域,则进一步按此形如“9a…”, “9b…”, “9c…”开头的形式做进一步的查找;如果只有此一顶级域名,则从“a…”获得该域名的授权DNS服务器IP,请求被进一步的前转到所查询域名的授权DNS服务器,在那里获知当前域名对应的IP数字地址。
分析比较与评估
NatureDNS系统使用一些新方法来实现使用自然语言进行扁平化的方式来表达域名地址。
Unicode,是国际组织制定的试图包括世界上所有文字和符号的字符编码方案,目标定位于满足用户在计算机输入的任何字符都能够使用Unicode表示出来。尽管Unicode本身也在发展进化中,但比起使用某一种语言的某个字符集而言,其稳定性相对较好。Unicode的实现方式之一UTF-8在互联网上得到广泛的使用。
ACE Punycode,这种算法满足了将Unicode 表示的多语种域名编码成ASCII 表示的域名,如此一来可以在不改变现有ASCII 域名协议的情况下,实现对国际化域名的支持,同时可以兼容旧的不支持Unicode的主机系统,为并行和过渡系统提供了可能。Punycode提供了较好的Unicode与ASCII互转的算法,除此,还可以考虑使用Base62x,实现类似功能 [21] 。
层级式,与现行DNS系统一样,NatureDNS继承了这一优点,发展和运行经验表明,这是一个稳定的结构,在负载分发、可用性和部署方式上都表现不错 [6]。
另外一点需要考量的是性能。NatureDNS对比现行DNS系统,在客户端增加了将非ASCII字符转为Punycode代码的开销,在服务器端增加对非ASCII字符的存储空间。在客户端进行字符串进行转码的操作是运行在每个独立的终端上,多一个转码步骤不会对DNS系统造成任何性能影响,一是运算处理是分布式地在每一台终端进行,二是Punycode代码是经过优选的算法,经过这一转码操作之后进入DNS轮询系统的只有Punycode。在NatureDNS的服务器端,在DNS记录集上,多增加一个数据字段,这对于目前的计算处理能力和存储空间来说,都是可以实现的。后期,在下文中会提到过渡方案,待到全部系统都支持Unicode(UTF-8)之后,Punycode转码就可以省略,服务器端的DNS记录也可以减去一个字段,整个DNS系统恢复到NatureDNS变更以前的状态。因此在NatureDNS开始部署及从DNS向NatureDNS过渡期间,客户端和服务器端可能会轻微地增加一些运算和存储,理论上推算增加一步Punycode转码或增加一列字段,都不会对系统造成严重影响。
与关键词寻址等比较
与关键词寻址、通用网址和IDN(国际化域名)的异同
总体来讲,除了现行的 .com 域名体系(标为0.),网民要在网上(主要是浏览器)上按某个名词/概念/想法去某个地方,大致另外可选的有四个方式:1. 关键词寻址(3721,现在已经不可用了),2.通用网址(“人民网”), 3.国际化域名(IDN)和新顶级域名(允许非ASCII字符出现.系域名系统中,升级和扩展之前的IDN),4.搜索引擎(万能的,比如谷歌的“feeling lucky”按钮)。加上 .系 域名(以.com为主),共五种方式,这些深度分析在这篇论文中有:NatureDNS:一种自然语言式域名寻址系统。
现在看来,网民常用的,只有 .com 或者 搜索引擎,如果人的惰性再持续增长,最后剩下的估计只有搜索引擎(或者变种的Siri,Cortana等个人智能助理)。
如果分一下类,1,2,4 属于一类(A) ,对要检索的名址,没有格式要求,如”大象”,”大象的鼻子”,”大象鼻子”,”象鼻子”,”长鼻子”等;0,3属于一类(B),对要检索的名址,有严格的格式要求(.系),如”ufqi.com.”(尾部,顶级域的.可以省略),”erp.sina.com.cn.”, “sf-express.com”等。
A类更符合人的使用习惯,但不够准确、规范,人能使用,计算机无法操作;B类准确、规范,但需要人额外的记忆一些东西,并需要在使用的时候做转换,比如中国人要去新浪,需要将”脑子”里的“新浪”转换为“sina”,“sina.cn”或者“sina.com.cn”。如同在物理世界中,要找张三,需要翻出他的地址(域名)或者电话(IP)一样,如“北京市海淀区北四环西路理想国际大厦…..”, “138xxxx8888”. 后两者,地址和电话,都不容易凭脑子记住(有时候是懒得记或者内容太多,脑体有限)地址(域名)和电话(IP),所以对搜索引擎(智能助理)的依赖,只会越来越严重。
从以上A、B分类来看,-NatureDNS 属于B类,有准确、规范的要求:以-开头,子域名以-隔开,如 “-ufqi”, “-ufqi-blog”, 这是 -NatureDNS 区别于 3721、通用网址等根本的区别之一。
第二,-NatureDNS 与同属 B 类的 .com 系,也有区别:-NatureDNS 没有“分类域”的概念,.com系有严格、规范的“二级域”(.是顶级域,其下 .com, .cn 等是二级域);每个新的二级域的开放,有一套漫长、严格的流程,如大家看到的newgTLD 的产生一样。-NatureDNS 没有“分类域”的概念,根域(-)之下,凭语言本身的语义来定义各自的“域”,“-联想集团”,“-hsbc” ,“-国家安全局” 其语义本身就已经定义了前两者是 commercial(.com),后者是state agency(.gov) ,为何还要多加附缀呢? 用”联想集团.政府” 能做什么呢?
第三,(本来有的,IDN扩大化之后,.com系 已经允许非ASCII字符出现在域名中了,这第三点区别显得不明显了)非ASCII被允许出现在域名中,是一大重要举措,但也看到,IDN只是权宜之计,离用户使用自然域名表达名址还有距离,其中一个障碍是 .(dot,表示stop)在一些语言中无法构成名址,而-NatureDNS 选用的 -(hyphen,表示connect),这也是我们经过考虑,选择 – 作为 -NatureDNS 的根域标记, 而不选择其他符号的原因。
过渡阶段的启用
过渡阶段在浏览器中启用自然域名(NatureDNS)的方法
在浏览器中启用对自然域名的支持,对公众来说具有很好的亲和性和便利性,免去记忆各种复杂、多级的英文域名,使用母语的品牌名称即可快速抵达,同时也是浏览器先进性的一种体现。
在浏览器中启用对自然域名的支持可以有两种方式:
1.将浏览器的默认搜索引擎设置为UFQI-NatureDNS[1],浏览器侦测到用户输入的是非常规域名时,请求UFQI-NatureDNS进行自然域名解析,域名匹配成功直接抵达目标站点,匹配不成功,继续前传请求到浏览器设定的“默认搜索引擎”进行搜索,并返回相应结果,该过程描述为:
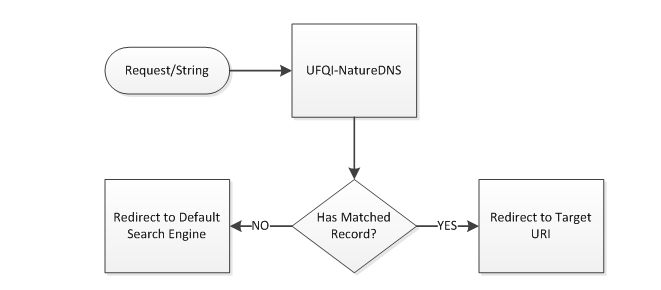
在浏览器中启用自然域名
Figure 1替换默认搜索引擎
2.在浏览器中内置用户输入字符串的过滤模块[2],如果用户输入了自然域名格式(/^\-[^\-]+[.*][^\-]+$/)的查询字符串则将请求发往UFQI-NatureDNS,否则按此前的流程将请求转给原来的默认搜索引擎,其过程可以描述为:
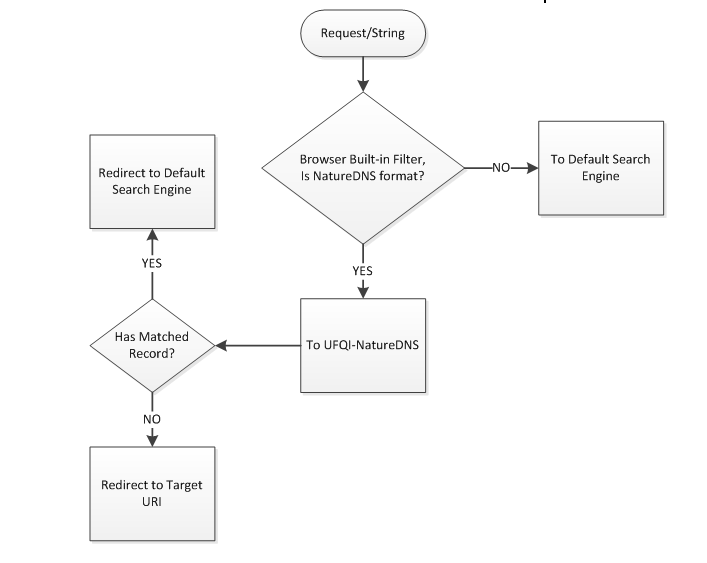
在浏览器中支持自然域名
Figure 2内置字符串判断模块







