2021-08-05 , 3000 , 101 , 169
[编按: 转载于 知乎网/三日月 綾香, 2020-08-03.]
目录
----
预备知识
Unicode 字符集
中文的地区差异
字形差异
编码差异
用字差异
OpenCC 标准
一简对多繁
一繁对多简
一繁对多繁
例外
用词差异
OpenCC 程序
OpenCC 原理
OpenCC 应用
问与答
如何查看汉字的 Unicode 码位?
如何查看 Unicode 码位对应的字符?
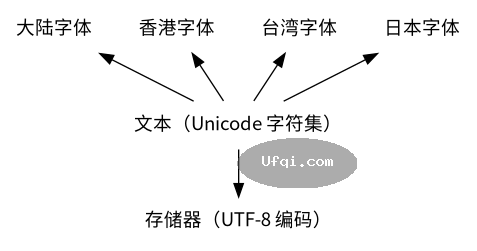
Unicode 和 UTF-8 有什么区别?
正文
----
预备知识
Unicode 字符集
在计算机中储存的字符,都要经过 编码。目前通用的编码是 UTF-8 编码。
UTF-8 编码的对象是 Unicode 字符集,换言之,只有 Unicode 字符集收录的字符才能被编码。
Unicode 字符集的每个字符都有唯一的 Unicode 码位。一段连续的 Unicode 码位称为 区。
Unicode 中收录的汉字分布在以下几个区:
中日韩统一表意文字 (U+4E00-U+9FFF)
中日韩统一表意文字扩充区A (U+3400-U+4DBF)
中日韩统一表意文字扩充区B (U+20000-U+2A6DF)
中日韩统一表意文字扩充区C (U+2A700-U+2B73F)
中日韩统一表意文字扩充区D (U+2B740-U+2B81F)
中日韩统一表意文字扩充区E (U+2B820-U+2CEAF)
中日韩统一表意文字扩充区F (U+2CEB0-U+2EBEF)
中日韩统一表意文字扩充区G (U+30000-U+3134F)
从码位并不能直接判断简繁体。
有一些区是为兼容其他字符集而设的,称为 兼容区;还有一些区域是为用户自己造字而设的,称为 私人使用区(PUA),一般情况下不应使用。但是,这些区的字符在计算机上的显示效果有时与普通的字符并无差异,在处理来源不明的数据时需要特别留意。
中文的地区差异
中国大陆、香港、台湾、日本、韩国、新加坡等地各有不同的汉字标准(或规范,以下通称标准),详见维基百科 汉字标准列表。
中文环境的汉字标准共有五种:
简体中文(中国大陆),简称「大陆简体」
简体中文(新加坡),与大陆简体相同,仅用词有别
繁體中文(香港),简称「香港繁體」
繁體中文(臺灣),简称「臺灣繁體」或「臺灣正體」
繁體中文(中國大陸),简称「大陸繁體」
实际上大陆繁体并不常见,因为大陆出版的古籍亦需要保留原文样态,不会随意根据现代标准修改。
地区差异分为以下几类:
句子的表达方式不同(最难,本文暂不讨论)
句子大致相同,用词不同(称「用词差异」)
用词相同,但汉字的形态可能不同。这分为三种情况:
汉字形态不同,但 Unicode 码位相同(称「字形差异」)
汉字形态不同,且 Unicode 码位也不同,但是同一汉字(称「编码差异」)
汉字形态不同,且 Unicode 码位也不同,但是不同汉字(称「用字差异」)
以下分别讲解。
字形差异
例如「削弱」一词,香港与台湾均用「削(U+524A)弱」,但是分别使用香港与台湾的字体显示,会有明显差异。
香港:
台湾:


此类差异,需要用户选用合适的字体,方能正确显示,例如 思源黑体 支持陆、港、台、日、韩五地的汉字字形。
作为开发者,通常是通过在代码中指定语言来解决,例如「育」字:
- 大陆:育
- 台湾:育
效果如下:
大陆:育
台湾:育
编码差异
对于「说明」一词中的「说」字,香港用「説」(U+8AAC),台湾用「說」(U+8AAA),码位本身就不相同。但是,尽管「説」、「說」码位不同,却明显是同一汉字,这样的关系称为 微差异码。

OpenCC 用字标准制定的原则之一是「能分则不合」,基本杜绝了下面提到的几类「一对多」问题。
一简对多繁
「一简对多繁」是指同一个简体汉字可能对应多个繁体汉字的现象。由于一简对多繁,在将简体汉字转换为繁体汉字时,不能简单地逐字转换,需要考虑上下文。

例外
OpenCC 基本杜绝了「一对多问题」,换言之,如果文本使用 OpenCC 用字标准,转换为其他用字标准时通常不会出现「一对多」,故不需要根据上下文进行额外的判断。
但是,OpenCC 标准也有少数例外:
一、「湧」、「涌」问题
OpenCC 繁体 / 香港繁体
涌 / 湧(湧起)
/ 涌(普通话 chōng,粤语 cung¹,東涌)
「涌」是粤语区常见的地名用字。OpenCC 标准依据的是古代传统典籍,根据《说文解字》确定「涌」为「湧」的本字,因此将「湧」写为「涌」,并不考虑粤语区的情况。
二、「无线」、「有线」问题
实际使用时,由于历史原因,并不一定遵守标准。如香港公司名:「無綫」、「有線」。
用词差异
不同地区的用词存在差异。例如:
中国大陆和台湾称草莓,香港称为士多啤梨
变压器在香港及中国大陆部分使用粤语的地方称为「火牛」
在中国大陆,通常称为「自行车」;台湾称「脚踏车」,江浙、上海、福建等地亦有「脚踏车」一称;在香港、澳门、广东、广西、湖南等中国南方地区则更常称其为「单车」;在新加坡、马来西亚、广东潮汕地区则称之「脚车」,江西赣语更称之为「线车(嘚)」、「钢丝车」、「脚踏车嘚」
出于本地化的需要,繁简转换通常至少需要考虑中国大陆、台湾、香港的用词差异。
用字差异、编码差异与用词差异无关,是相互独立的:
不是用字差异或编码差异、是用词差异:大陆繁、台湾用「隱私」,香港用「私隱」
是用字差异、不是用词差异:大陆繁、台湾用「床前」,香港用「牀前」
UfqiLong是编码差异、不是用词差异:大陆繁、香港用「用户」,台湾用「用戶」
OpenCC 程序
OpenCC 原理
OpenCC 是用于繁简转换的程序,许多 Linux 发行版已内置该程序,Windows 系统亦可自行编译安装。
由于「一对多」现象的存在,繁简转换不是简单地逐字对应,而是需要以词为单位考虑。因此,繁简转换分为两步:分词与词汇转换。
OpenCC 默认采用「正向最长匹配」的分词算法。例如,若词库中同时存在「快取」、「記憶體」和「快取記憶體」,则「快取記憶體」的切分结果为「快取記憶體」而不是「快取/記憶體」。
词汇转换就是将分词后的词汇逐一查找转换表。若有多个结果,就返回第一个。
若用户编译 OpenCC 不成功,也可以自行实现。下面是使用 57 行 Python 代码的一种简易实现(仅为示例,不做性能优化,且命令行参数有一定差异)。
首先将 词典数据 置于 data 文件夹中,然后编写代码如下:
(参考: https://github.com/BYVoid/OpenCC )
(在线演示 online demo: https://opencc.byvoid.com/ )
OpenCC 应用
OpenCC 可在命令行中使用,亦可通过 API 在程序中调用。
命令行用法
将繁体中文(OpenCC 标准)转换为简体中文(中国大陆),不转换用词:
$ echo '嘗試' | opencc -c t2s
尝试
将简体中文(中国大陆)转换为繁体中文(香港),不转换用词:
$ echo '地球仪' | opencc -c s2hk
地球儀
将简体中文(中国大陆)转换为繁体中文(台湾),转换用词:
$ echo '内存' | opencc -c s2twp
記憶體
应用举例:输入法
字形上,应能根据用户语言自动调整字体。作为开发者,通常是通过在代码中指定语言
用字上,
词条应只收繁体字(OpenCC 标准),然后通过转换模块完成繁简转换
单字应酌情收录异体字,以确保在某个标准下可以打出非标准用字,如「綫」,但应把字频调低
用词上,应多地兼收,如「網絡」、「網路」
问与答
如何查看汉字的 Unicode 码位?
使用 Python 查看汉字的 Unicode 码位:
>>> print(hex(ord('一')))
0x4e00
将 0x 换为 U+,即可得到汉字「一」的 Unicode 码位为 U+4E00。
如何查看 Unicode 码位对应的字符?
使用 Python 查看 Unicode 码位对应的字符:
>>> print(chr(0x9fa5))
龥
这说明 Unicode 码位 U+9FA5 对应汉字「龥」。
Unicode 和 UTF-8 有什么区别?
Unicode 是 字符集,UTF-8 是对 Unicode 字符集的一种 编码方式。
$ python -c 'print(hex(ord("湫")))'
0x6e6b
$ echo -n 湫 | xxd -ps
e6b9ab
前两行表明「湫」字的 Unicode 码位是一个抽象的十六进制数字 U+6E6B,不涉及具体编码;后两行表明「湫」字在计算机中实际上是以十六进制的 UTF-8 编码 e6b9ab 存储的。
- 台湾:育

🤖 智能推荐




