... 2023-10-02 01:30 .. 所有数据集都与同一个大模型(LLaMA-2-70B-chat)对齐,从而实现了交错式多模态上下文提示。
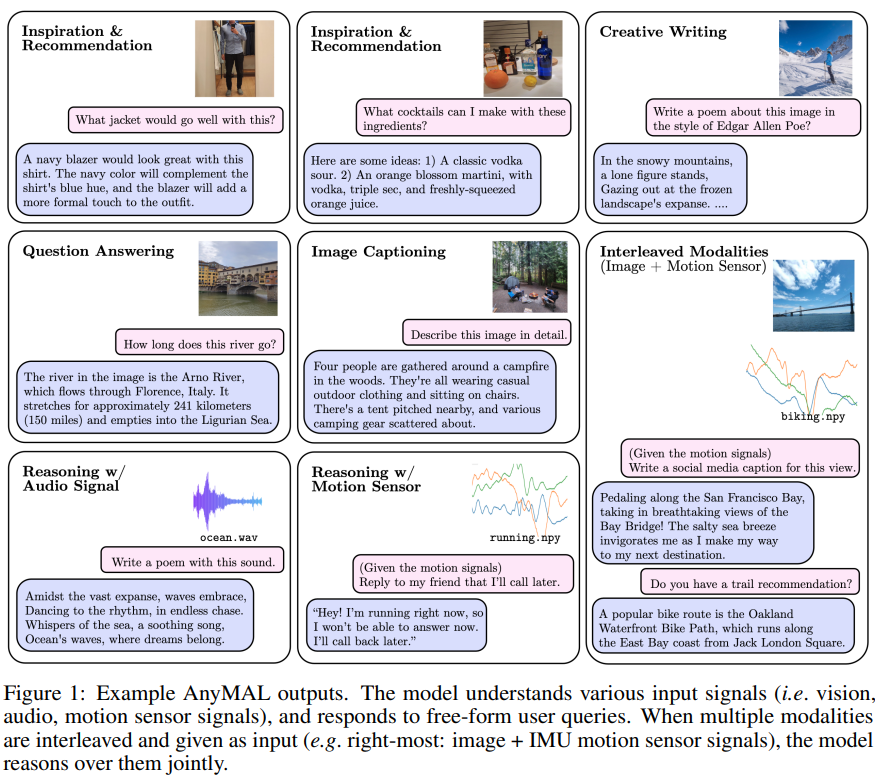
本文利用跨三种模式(图像、视频和音频)的多模态指令集对模型进行了进一步微调,涵盖了简单QA领域之外的各种不受约束的任务。
该数据集具有高质量的人工收集指令数据,因此本文也将其作为复杂多模态推理任务的基准。
与现有文献中的模型相比,本文最佳模型在各种任务和模式的自动和人工评估中都取得了很好的零误差性能,在VQAv2上提高了7.0%的相对准确率,在零误差COCO图像字幕上提高了8.4%的CIDEr,在AudioCaps上提高了14.5%的CIDEr,创造了新的SOTA。
方法方法概览预训练模态对齐本文使用配对的多模态数据(特定模态信号和文本叙述)对LLM进行预训练,从而实现多模态理解能力,如图2所示。
具体来说,研究为每种模态训练一个轻量级适配器,将输入信号投射到特定L .. UfqiNews ↓
1

...在2022年9月生数科技创始成员也提出了基于Transformer的网络架构U-ViT,这与Sora在架构思路与实践路径上完全一致.
值得一提的是,CVPR2023曾因“缺少创新性”将DiT拒稿,而选择收录了U-ViT.
生数科技在2023年3月开源的自主研发的UniDiffuser模型同样采用了Transformer+Diffusion的融合架构,可以在文、图两种模态之间进行转换,在参数量和训练数据规模上对齐StableDiffusion,能够实现图生文、图文联合生成、图文改写等多种功能.
在图文模型的训练中,生数科技参数量从最早开源版的1B不断扩展至3B、7B、10B及以上,使得模型在美学性、多元风格、语义理解等方面实现快速稳定的提升.
在此基础上,通过拓展空间维度和时间维度,逐步实现3D生成和视频生成模型的训练.
去年9月,生数科技推出了基于统一的多模态多任务框.. 03-13 04:00 ↓ 16
...模型给出的整个画面的结构、人与物品的关系都非常合理,使观者眼前一亮.
而对于同样的提示,我们来看一下当前最先进的SDXL和DALL·E3的表现:再看一下新框架面对多个对象绑定多个属性时的表现:Fromlefttoright,ablondeponytailEuropegirlinwhiteshirt,abrowncurlyhairAfricangirlinblueshirtprintedwithabird,anAsianyoungmanwithblackshorthairinsuitarewalkinginthecampushappily.从左到右,一个穿着白色衬衫、扎着金发马尾辫的欧洲女孩,一个穿着印着小鸟的蓝色衬衫、棕色卷发的非洲女孩,一个穿着西装、黑色短发的亚洲年轻人正开心地在校园里散步.
研究人员将这个框架命名为RPG(Recaption,PlanandG.. 02-17 03:40 ↓ 12 ..UfqiNews
本页Url
🤖 智能推荐
生数科技完成数亿元融资,年内复现 Sora,加速多模态进程 16
文生图新SOTA!Pika北大斯坦福联合推出RPG,多模态助力解决文生图两大难题 12
vivo开发者大会发布“蓝心智能”AI战略 原系统5全新升级 7
界面财联社入局AI 国内首个千亿参数多模态金融大模型面市 5
解题智实融合、音视频交互新挑战,AI 2.0时代怎么做? 4
🔥 相关精选
 全球3809支队伍角逐 IKCEST第五届“一带一路”国际大数据竞赛在渝落幕
4
全球3809支队伍角逐 IKCEST第五届“一带一路”国际大数据竞赛在渝落幕
4