-
02-28 10:40...令人感受到沪上人工智能发展的敏捷性和紧迫感。开发者是人工智能技术进步和产业发展的重要推动力量。在广大开发者的推动下,人工智能飞速发展,尤其是近期开源大模型技术和产品加快突破,为我国人工智能产业发展带来新机遇和新空间。本届全球开发者先锋大会旨在促进AI产业集群培育,推动基础大模型与算力、语料、垂类应用场景等AI企业深度融... 0
-
02-28 10:20...要深入贯彻习近平总书记关于安全生产、森林草原防灭火的重要指示批示精神,按照国务院视频会议部署和市委要求,坚持人民至上、生命至上,坚持底线思维、极限思维,以“时时放心不下”的责任感和“事事心中有底”的执行力,把安全工作想在前、谋在前、干在前,坚决守牢城市安全防线,为推动高质量发展营造高水平安全环境。龚正指出,去年,上海安... 0
-
02-28 10:20...是AI科创领域的一颗新星。截至2月上旬,MiniMax以每日生成数百万条视频占据全球第一,每日生成语音量位列国内前二,文本处理量也居国内前列。今年全球开发者先锋大会上,上海稀宇科技举办了技术交流论坛,与学界、业界专家以及全球开发者社区代表、AI创作者代表等,共同探讨AI前沿技术、应用场景与未来趋势。“通用人工智能不是简... 0
-
02-28 10:10...市委科创委办公室主任、市科技创新局局长张林就深圳打造最好科技创新生态和人才发展环境总体情况作介绍,并与市发展改革委主任郭子平、市人工智能产业办主任林毅、市人才工作局局长罗冰就如何优化深圳创新生态、精准优化营商环境、推动人工智能和人形机器人产业发展、持续优化人才政策等方面答记者问。市委宣传部副部长苏荣才主持新闻发布会。发... 0
-
02-28 05:40...远低于闭源模型GPT-4o的投入,但性能在多个测评中却与之相当。这使得大模型领域从“重资本游戏”走向“全民共创平台”。DeepSeek-R1开源后,AI大模型社区HuggingFace成功对其进行了复现,这也是中国AI大模型首次被复现。全球多家企业已经宣布接入DeepSeek或以DeepSeek为基础引擎,开发出特有的... 0
-
02-28 04:50...围绕项目系统化推进、全周期服务、协同化攻坚,紧盯关键节点、抓住关键问题、聚焦关键项目,以“起步即冲刺、开局即决战”的奋进姿态,全力以赴跑好开年“第一棒”。截至目前,海安市一季度将新开工亿元以上重大产业项目共20个,其中5亿元以上项目12个;朗肯、亚威、海太等6个项目入选2025年省重大项目,38个项目入选市重大项目,入... 0
-

-
02-28 04:50...继DeepSeek之后,全球AI开源浪潮涌动。开源模型优势凸显世界经济论坛网站称,有了开源AI的坚实支撑,开发人员能将宝贵资源打造成专业应用程序,从而释放AI解决实际问题的能力。报道援引科技风险投资家马克·安德森的评论称,作为一个开源AI模型,DeepSeek是他见过的最令人惊叹的突破之一,它无疑是赠予世界的一份厚礼。... 0
-
02-28 04:30...有可能从根本上打破美国OpenAI和软银集团(SBG)等将启动的AI研发项目“星际之门(Stargate)计划”等美国的封闭研发体制。对“低成本”的强调可能过于夸张DeepSeek的最新AI模型“R1”最初被隆重地报道为是以“压倒性的低成本”研发的。部分媒体报道了560万美元这一极低的研发费用,但DeepSeek方面解... 0
-
02-28 03:20...而不会相应地增加计算成本。发表评论:专家并行的难点在于专家之间的通信效率,DeepEP代码库重点解决了这一问题。通过优化的通信方案,DeepEP显著降低了专家之间数据交换的开销,提升了模型并行处理能力和训练推理效率。在MoE架构中,两个关键操作是分发(dispatch)和合并(combine)。1)分发:根据门控网络的... 0
-
02-28 03:00...DeepSeek将陆续开源5个代码库,以完全透明的方式与全球开发者社区分享他们在探索通用人工智能(AGI)领域的进展。DeepSeek的低成本、高性能特性带动AI渗透率全社会加速,随着开源代码的逐步发布,有望进一步带动各个行业应用的加速发展,以及算力端需求的增长。开源成趋势在人工智能大模型领域,开源与闭源的争论一直是行... 0
-
02-28 02:20...并投资未来。相关措施获各界赞同,认为可为香港未来发展提供可持续财政基础。香港特区行政长官李家超表示,财政预算案在改善公共财政方面提出务实措施,以严格控制政府开支为主,开源为辅,稳步恢复收支平衡,同时顾及社会实际情况和香港的竞争力。香港中华厂商联合会表示,由于香港公共财政连续几年出现赤字,财政预算案提出“强化版”财政整合... 0
-
02-27 13:20...与自主研发的“智慧体”应用有效整合,以人工智能AI科技力量重塑医疗服务的智慧化体验,打造AI医院建设新生态。AI导诊:自研“智善医芯”让就医少走“冤枉路”“咳嗽该挂呼吸科还是耳鼻喉科?腹痛要看消化科还是外科?”这些困扰患者的就医选择题,如今在山大二院有了智能解决方案。医院创新推出自主研发的AI导诊智慧体“智善医芯”,深... 0
-
-
02-27 10:20...深圳宣布实施“开源合伙人”支持计划,打造科创开源之城。早在去年10月,武汉就发布了全国首个开源建设方案并提出,入选优秀开源软件项目,直接奖励30万元,从政策到资金再到人才培养,全方位“保驾护航”。以往政府部门评审,证书、论文、专利是“硬通货”,但这次武汉玩起了新花样。“开放度、活跃度……这些以前从没出现过的软性指标,成... 0
-
02-27 10:20...其工具在全球编程语言分析网站PLDB排行榜上,跻身前200名。在开源世界,大家用独特的代码语言“兼济天下”。丁尔男说,现在,武汉的政府部门也学会了这门“语言”,用全新的眼光看待这些开源项目。何谓开源?DeepSeek发布的R1模型,开源后通过全球开发者的验证。开源也日益成为数字时代全球分工体系的主流模式。上海说,要成为... 0
-
02-27 10:10...武汉杉杉奥特莱斯是杉杉商业集团在全国布局的第21座奥莱综合体。据介绍,项目引入了“雾森系统”,夏季室外走廊屋顶会自动喷雾,营造凉爽舒适的购物环境。此外,广场上还设计了4个亲子戏水区,孩子们可以尽情嬉水玩乐。此外,绿化设计贯穿整个庭院,室内外绿植交相辉映,打造出“城市微度假”般的自然体验。武汉杉杉奥特莱斯总经理刘亮介绍,... 0
-
02-27 09:40...而政策制度的完善将为人工智能创新提供更加有利的环境。王文认为,“DeepSeek的开源模式促进了良性竞争,为不同领域的新企业提供了成长土壤。这种模式的成功不仅限于DeepSeek,未来更多公司,甚至其他行业的企业预计也会采用这一模式,人工智能的多个领域都将因此受益。”复旦大学特聘教授窦德景则强调了大模型的重要性。生成式... 0
-
02-27 08:20...那就是精度比较低。如果说高精度格式是无损压缩,那FP8就是有损压缩。大幅减少存储空间但需要特殊的处理方法来维持质量。而由于精度低,就可能产生量化误差,影响模型训练的稳定性。在报告中DeepSeek介绍:“目前,DeepGEMM仅支持英伟达Hopper张量核心。为了解决FP8张量核心积累的精度问题,它采用了CUDA核心的... 3
-
02-27 04:30...也可能正在面临B端第二增长逻辑不通的可能,美图公司在2023年首次发布基于中小企业的B端市场AI大模型,意图开拓中国海量的中小企业AI数字化营销市场,这也成为公募基金持续重仓美图公司,以及该股股价突破的一条重要基本面逻辑,但在deepseek开源后不久,2月25日,美图公司(01357)发布公告,公司第一大股东蔡文胜于... 5
-
-
02-27 02:50...系列模型在开源社区很受欢迎;Google则采取了混合策略,核心模型Gemini为闭源产品,但也同时开源了Gemma等小型模型。在国内市场情况也类似,百度、月之暗面等采取闭源策略,阿里、DeepSeek采取开源策略,智谱、百川智能等与Google路径相似,把小参数模型开源,核心模型仍保持闭源。此前,闭源的路径似乎更受企业... 0
-
02-27 02:40...AI教育有望迎来加速发展期。核心逻辑1.AI引领教育变革,国内商业化进程有望加速。教育是较为容易实现AI赋能且有望产生长远变革的重要场景,海外多款AI+教育爆品已跑通,随AIAgent纪元的到来,叠加以DeepSeek为代表的高性能、低成本、开源国产大模型的涌现,乐观看待国内具有强产品力+清晰商业模式优势的头部教育公司... 0
-
02-27 02:30...离DeepSeek疯狂发酵仅有数周,软硬件适配、测试、上架等工程都需要时间,目前公司对外合作的项目还未落地,因此具体成本数据暂不清晰。在AI的潮汐效应下,接入DeepSeek是否一本万利,还需让子弹再飞一会儿。接入模型并非“量”的比拼目前来看,企业接入DeepSeek的程度有所不同。2月13日,继微信、腾讯文档、QQ浏... 0
-
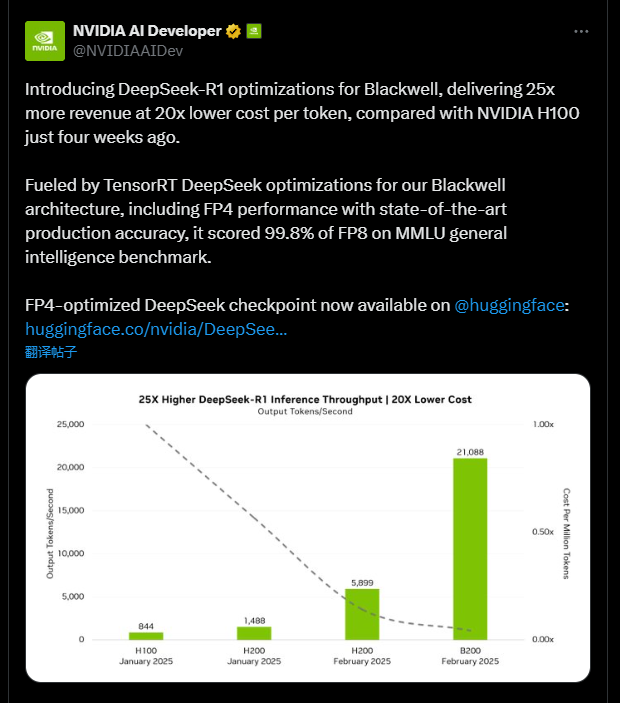
02-27 02:30...相较于仅四周前的NVIDIAH100,该方案实现单token成本降低20倍的同时,性能提升25倍。具体看,在新模型的加持下,B200实现了高达每秒21,088token的推理吞吐量,相比于H100的每秒844token,提升了25倍。通过TensorRT对Blackwell架构的深度优化,在保持业界领先生产级精度的前提... 0
-
-



-
本页Url:
-
2025-03-01-18:36 GMT . 添加到桌面浏览更方便.
-

