-
02-09 19:00...全球范围内,各国AI技术人员掀起“DeepSeek复现热潮”,充分验证了中国大模型的“物美价廉”。在国内,多家公司的产品研发团队进行DeepSeek大模型国产化适配,基于国产昇腾芯片完成DeepSeek-R1模型运行验证,实现了技术链路100%国产化,确保全栈自主可控。花小钱办大事,不仅证明了中国在人工智能领域的技术创... 0
-
02-06 20:20...一是以技术创新降低了模型训练成本,颠覆了“大力出奇迹”、单纯依赖堆算力和数据实现模型优化的传统路径,一定程度上动摇了行业对硬件的崇拜;二是以开源打破了以OpenAI为首的闭源模型的技术垄断,使得AI开发与应用从少数人的专利变成多数人的狂欢。降本与开源,是DeepSeek出圈的两大核心密码。因此,有科技从业者慨叹,“De... 4
-
02-06 18:40...颠覆了“大力出奇迹”、单纯依赖堆算力和数据实现模型优化的传统路径,一定程度上动摇了行业对硬件的崇拜;二是以开源打破了以OpenAI为首的闭源模型的技术垄断,使得AI开发与应用从少数人的专利变成多数人的狂欢。降本与开源,是DeepSeek出圈的两大核心密码。因此,有从业者慨叹,“DeepSeek以算法优化击碎了硬件霸权,... 2
-
02-02 02:40...我们站在了历史错误的一边,需要制定不同的开源策略。”奥尔特曼在谈到DeepSeek时说:“这是一个非常好的模型。我们会发展出更好的模型,但我们将不如前几年,保持那么大的领先优势。”大公报记者苏雨润、凯雷北京报道仅用OpenAI预算5%彰显中国人才优势DeepSeek大模型训练成本不到600万美元,仅为OpenAI训练C... 3
-
01-31 22:10...据创投机构援引OpenAI文件显示,该公司预计到2029财年才可以实现盈利,届时收入将达到1000亿美元。其中,ChatGPT收入为500亿美元,API(应用程序编程接口)销售与新产品项目将各自产生250亿美元的收入(见配图)。拆穿美科企估值泡沫然而,与1月20日DeepSeek发布的R1推理模型相比较,在多个逻辑任务... 0
-
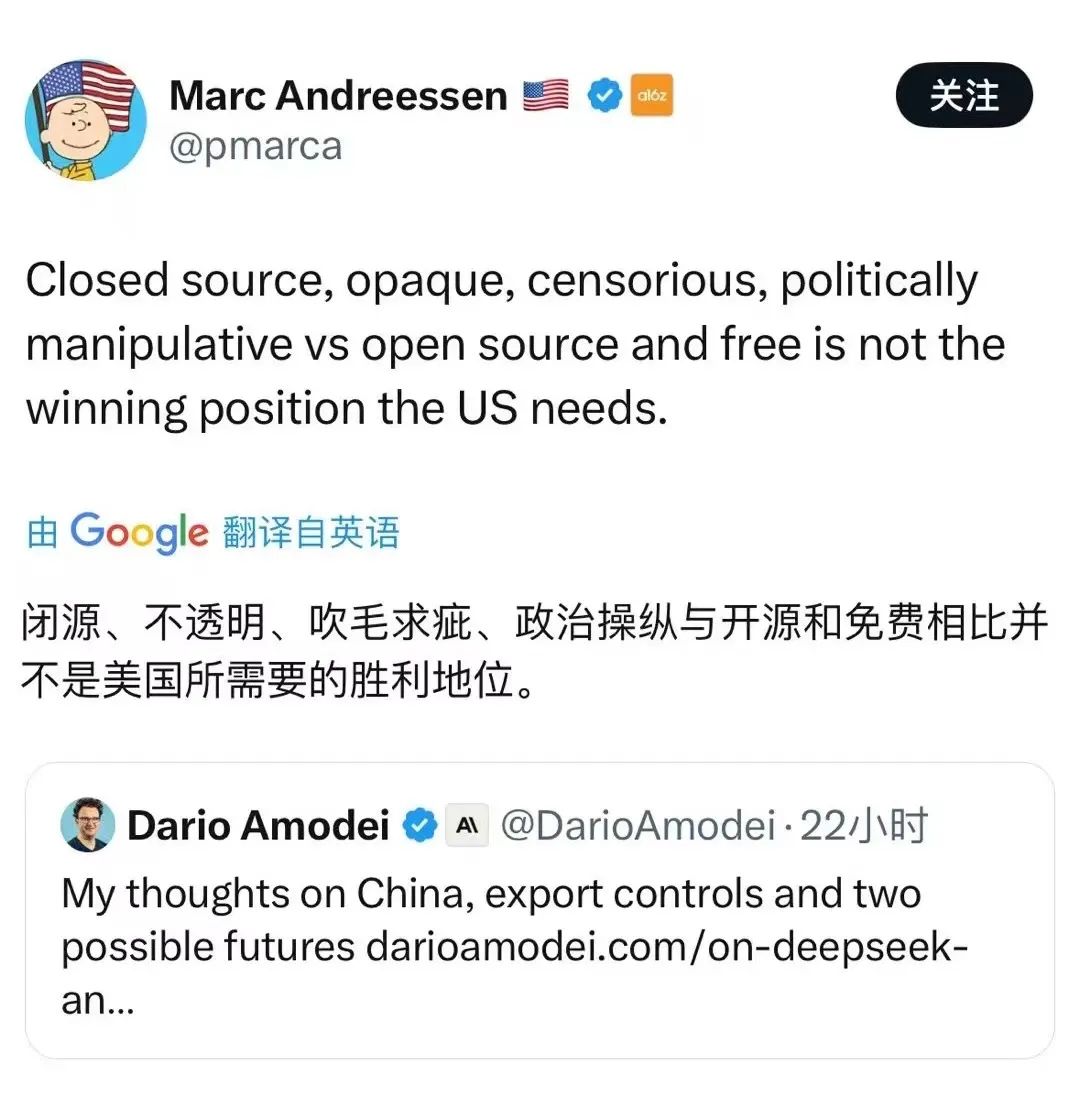
01-31 19:30...MarcAndreessen在社交平台表示:“DeepSeekR1是我见过的最令人惊叹、最令人印象深刻的突破之一,并且是开源的,是给全世界的礼物。”当天,英伟达股票下跌超3%,华尔街开始注意到DeepSeek这匹AI黑马,发现AI模型或许不需要依靠堆积算力就能取得卓越性能,从而打破了美股这两年来在AI浪潮中形成的“算力... 0
-

-
01-29 09:20...从行业发展的逻辑来看,探索与迭代、追赶所需的算力成本不应简单对比。创新和探索必然伴随着算力和各项成本的浪费,在确定性路径上的优化所付出的代价与探索未知所付出的代价不宜直接比较。现阶段大模型的发展还不能定义为闭源与开源路线的成败。更严谨地看待DeepSeek带给我们的惊喜,应该是:它展示了模型架构底层创新的价值,提升了算... 4
-
01-27 23:30...激活参数为370亿,在14.8万亿token上进行了预训练。V3在知识类任务上接近当前表现最好的Claude-3.5-Sonnet-1022,在代码能力上稍好于后者,并且在数学能力上领先其他开闭源模型。更重要的是,DeepSeek-V3的总训练成本仅为557.6万美元,完整训练消耗了278.8万个GPU小时,几乎是同等... 0
-
01-27 19:50...和相关技术2023年11月2日DeeSeek推出首个模型DeepSeekCoder该模型免费供商业使用且完全开源2023年11月29日DeepSeekLLM上线其参数规模达到67B性能接近GPT-4同时还发布了该模型聊天版本DeepSeekChat2024年5月DeepSeek-V2发布该模型在性能上比肩GPT-4Tu... 16
-
01-25 18:50...5Sonnet那些顶尖的闭源模型差不多。这样一来,开源模型在性能方面就不像以前那样跟闭源模型差得老远啦,把开源模型整体的竞争力都提高了,给开发者和企业在挑模型的时候,提供了更划算的开源选择。第二、会推动开源社区发展:DeepSeekV3完完全全开源啦,像训练的细节、代码啥的都有,这能吸引来更多的开发者参与到这个模型的研... 1
-
01-15 10:30...美国商务部发布了名为《人工智能扩散框架》的临时最终规则,对先进计算芯片以及闭源AI模型的出口实施新的管控措施,主要规则在120天后开始执行。具体来看,美国将全球国家和地区划分为三类,出台不同的限制措施,对中国大陆等的AI芯片采购实施严格管控。新增闭源AI大模型的出口限制,对美国数据运营公司的全球算力部署进行限制。中信证... 3
-
01-15 10:20...美国商务部发布了名为《人工智能扩散框架》的临时最终规则,对先进计算芯片以及闭源AI模型的出口实施新的管控措施,主要规则在120天后开始执行。具体来看,美国将全球国家和地区划分为三类,出台不同的限制措施,对中国大陆等的AI芯片采购实施严格管控。新增闭源AI大模型的出口限制,对美国数据运营公司的全球算力部署进行限制。中信证... 6
-
-
01-14 17:30...以色列、新加坡、沙特等第二级国家地区只有聊胜于无的进口配额,他们的企业想多进口就得“特事特办”向美国申请;包括中国在内的第三级则被全面禁止进口高端显卡和先进闭源大模型。“把打游戏的设备都禁了”美国搞这么大动静,目的是防止先进芯片直接或间接流入中国大陆,维持自身AI霸权。但这种“为你舍弃全世界”的打法,是封杀中国,还是封... 11
-
12-29 17:30...”前OpenAI联创、知名AI科学家AndrejKarpathy在其个人社交平台上表示,DeepSeek-V3整个训练过程仅用了不到280万GPU小时,相比之下,Meta旗下顶尖的开源模型Llama-3405B的训练时长是3080万GPU小时。如果DeepSeekV3的优良表现能够得到广泛验证,那么这将是资源有限情况下... 5
-
09-18 04:00...另两名创始人——纪尧姆·朗普勒和蒂莫泰·拉克鲁瓦此前任职于脸书母公司“元”的AI团队。三人曾是大学同窗。米斯特拉尔人工智能公司主要开发基于自然语言处理、机器视觉和深度学习的生成式AI技术。成立仅一年多,60人左右的团队已推出数款AI语言模型。目前,该公司正在加速发展自然语言处理技术,尤其关注多语种能力,以反映欧洲语言的... 0
-
09-11 10:40...即理解能力、生成能力、逻辑推理能力、记忆能力等基本能力上的差距;二是成本方面,有些模型虽能达到同样效果,但成本高、推理速度慢,还是不如先进模型。此外就是对于测试集的over-fitting(过拟合),他指出很多模型为了证明自己,会在发布之后去打榜,会去猜测试题目、答题技巧。从榜单上看,或许模型的能力已经很接近了,“但到... 14
-
07-06 04:40...通义千问-Max得分追平GPT-4Turbo,是该基准首次录得国产大模型取得如此佳绩。去年8月,通义率先加入开源行列,沿着“全模态、全尺寸”开源路线陆续推出了数十款模型,包括语言大模型、多模态大模型、混合专家模型、代码大模型等,在权威榜单多次创造中国大模型的“首次”。通义千问最新推出的开源模型Qwen2-72B更是风靡... 0
-
07-05 18:20...支持侧边指纹,主打轻薄设计。作为参考,荣耀MagicV2薄至9.9mm,因此全新荣耀MagicV3系列折叠屏手机有望在此基础上更轻薄。新机首发AI离焦护眼技术,将端侧AI与屏幕相结合,可根据用户用眼环境和习惯,通过模拟离焦镜效果来优化屏幕显示,以减轻视觉疲劳。号称”阅读25分钟短暂性近视指标最大降低75度。“其他配置方... 4
-
-
07-05 18:20...人工智能的未来需要开放的生态系统和共同治理,他们期待与合作伙伴共同推动AI向善,创造美好未来,并宣布将举办人工智能生态论坛,发布AI生态合作计划和产品。中国移动董事长杨杰在演讲中强调了AI作为新生产力的重要性。他认为AI大模型能通过整合社会全量知识,形成超越人类的逻辑推理能力,加速经济社会发展。中国移动致力于推进AI深... 1
-
06-16 23:10...刚刚在全新的大模型测评基准LiveBenchAI中,进入榜单前列的阿里云通义千问开源大模型Qwen2-72B。榜单显示,LiveBenchAI首次针对34个全球领先的开闭源大模型进行测试评价,GPT-4o排名第一,紧随其后的有Cluade-3、Gemini-1.5和Qwen2-72B,其中Qwen2-72B是排名最高的... 7
-
05-19 19:40...「Her」真的来了:「GPT-4o」将语音助手带到了新高度多模态融合模型,只是工程的进步吗?OpenAI发布了新一代旗舰模型GPT-4o,它可以让人们在手机上与ChatGPT对话,就像他们与Siri和其他语音助手对话一样。不同的是,ChatGPT语音助手的理解能力有了质的飞跃,还可以分析和讨论它所看到的图像或视频,并能... 0
-
05-17 21:00...非在线营销业务给百度贡献了68亿元营收,同比增长6%,主要由智能云业务带动。针对本季度表现,百度CEO李彦宏表示,“随着生成式人工智能时代在中国的到来,文心大模型等基础模型将成为基础设施,融入人们生活的方方面面。我们正在让文心大模型系列变得更加实惠和高效。这将为百度带来更多机遇”。百度CFO罗戎表示,“2024年一季度... 8
-
-



-
本页Url:
-
2025-02-11-06:22 GMT . 添加到桌面浏览更方便.
-

