-
02-01 02:10...美国开放人工智能研究中心联合创始人伊利亚·苏茨克维尔在去年12月举行的机器学习会议上声称,AI行业已触及他所称的“数据峰值”,AI的训练数据如同化石燃料一样面临着耗尽的危机。此外,有研究预测,到2026年,ChatGPT等大型语言模型的训练将耗尽互联网上所有可用文本数据,届时将没有新的真实数据可供使用。为给AI提供充足... 0
-
02-01 00:30...KraneShares金瑞中证中国互联网ETF周三资金流入规模创近四个月来最大。数据显示,这只ETF单日资金流入1.05亿美元,创去年10月3日以来最大。从消息面看,近期,中国人工智能(AI)企业深度求索(DeepSeek)发布其最新开源模型DeepSeek-R1,用较低的成本达到了接近于美国开放人工智能研究中心(Op... 0
-
01-31 23:20...刚刚注册帐号的DeepSeek创始人梁文峰(目前还无法验证该帐号的真实性)也宣布了此消息。已经有不少网友尝试过该模型了,比如生成一个看起来像网球的小鸟,绒毛形态十分逼真。或者由「美丽的汉字」五个字符组成的图画:这个同时兼具视觉理解和生成的模型着实再一次震惊了中外AI社区,毕竟这个表现如此卓越的模型仅有7B大小!论文标题... 0
-
01-31 22:10...据创投机构援引OpenAI文件显示,该公司预计到2029财年才可以实现盈利,届时收入将达到1000亿美元。其中,ChatGPT收入为500亿美元,API(应用程序编程接口)销售与新产品项目将各自产生250亿美元的收入(见配图)。拆穿美科企估值泡沫然而,与1月20日DeepSeek发布的R1推理模型相比较,在多个逻辑任务... 0
-
01-31 20:40...其中较小版本的Llama4Mini已完成预训练,更强大的版本正在紧锣密鼓地开发中。Llama4的目标是实现原生多模态能力和Agent能力,开启众多全新应用场景,预计Llama4将成为2025年最先进和应用最广泛的AI模型。同时,Meta还计划打造一个强大的AIEngineeringAgent,使其编程和问题解决能力媲美... 0
-
01-31 20:20...还有一个重要的因素——中国AI技术的实力再度获得全球认可。1月29日,阿里云通义千问旗舰版模型Qwen2.5-Max正式升级发布。据其介绍,Qwen2.5-Max模型是阿里云通义团队对MoE模型的最新探索成果,预训练数据超过20万亿tokens,展现出极强劲的综合性能,在多项公开主流模型评测基准上录得高分,全面超越了目... 0
-

-
01-31 19:50...同时还提供了高推理效率。为了帮助开发人员安全地试验这些功能并构建自己的专用代理,6710亿参数的DeepSeek-R1模型现已作为NVIDIANIM微服务预览版在Build.nvidia.com上提供。DeepSeek-R1NIM微服务可以在单个NVIDIAHGXH200系统上每秒提供多达3872个令牌。开发人员可以使... 0
-
01-31 19:30...MarcAndreessen在社交平台表示:“DeepSeekR1是我见过的最令人惊叹、最令人印象深刻的突破之一,并且是开源的,是给全世界的礼物。”当天,英伟达股票下跌超3%,华尔街开始注意到DeepSeek这匹AI黑马,发现AI模型或许不需要依靠堆积算力就能取得卓越性能,从而打破了美股这两年来在AI浪潮中形成的“算力... 0
-
01-30 04:50...DeepSeek-R1-Zero的平均pass@1得分从最初的15.6%跃升至令人印象深刻71.0%,达到与OpenAl-o1-0912相当的性能水平。这一重大改进突显了我们的RL算法在优化模型性能方面的有效性。”但R1zero本身也有问题,因为完全没有人类监督数据的介入,它会在一些时候显得混乱。为此DeepSeek用... 0
-
01-29 21:20...与国际知名大模型相比,其成本大约低了一个数量级。高盛集团也认为,DeepSeek新模型的成本远低于现有模型,这意味着开发利用大模型的门槛降低,互联网巨头将面临初创公司的潜在竞争。英国《金融时报》发表的一篇评论文章指出,DeepSeek挑战了人工智能产业在过去一段时间的核心信念,即认为更强大的硬件才是推动人工智能发展的关... 0
-
01-29 17:50...5-7B-Instruct-1M和Qwen2.5-14B-Instruct-1M,首次将开源的Qwen模型的上下文扩展到1M长度。为了帮助开发者更高效地部署Qwen2.5-1M系列模型,Qwen团队完全开源了基于vLLM的推理框架,使得该框架在处理1M标记输入时的速度提升了3倍到7倍。点评:构建通用人工智能(AGI)是... 0
-
01-29 12:20...按照实际支付算力费用不超过20%的比例,给予企业最高100万元补贴。推进开源技术发展,建设优秀开源社区、开源平台、开发测试平台等,推动一批基础性、前瞻性开源项目在重点应用场景落地,对被国家级开源基金会接受的捐赠项目给予奖励。推进5G网络在工业企业、园区的深度覆盖,支持企业牵头开展行业共性数据资源库建设、行业产品主数据标... 2
-
-
01-29 09:20...从行业发展的逻辑来看,探索与迭代、追赶所需的算力成本不应简单对比。创新和探索必然伴随着算力和各项成本的浪费,在确定性路径上的优化所付出的代价与探索未知所付出的代价不宜直接比较。现阶段大模型的发展还不能定义为闭源与开源路线的成败。更严谨地看待DeepSeek带给我们的惊喜,应该是:它展示了模型架构底层创新的价值,提升了算... 0
-
01-29 08:50...它拥有强大的自然语言处理能力,能够理解并回答你的问题,就像你和朋友聊天一样自然流畅。而且,DeepSeek不仅能聊天,还能帮你写代码、整理资料,甚至能帮你解决一些复杂的数学问题。它背后有着复杂的算法和大量的数据支持,就像是一个经验丰富的侦探,能从海量信息中挖掘出你想要的东西。关于类似的大模型,最广为人知的可能是Open... 0
-
01-29 08:20...在数学、代码、自然语言推理等任务上的性能比肩OpenAI的o1模型正式版。据DeepSeek介绍,R1的预训练费用只有557.6万美元,远低于OpenAIGPT-4o模型的训练成本。加利福尼亚大学伯克利分校教授亚历克斯·迪马基表示,DeepSeek的技术路线揭示了一个事实:达到顶尖性能未必需要巨额投入,这对硅谷的烧钱竞... 0
-
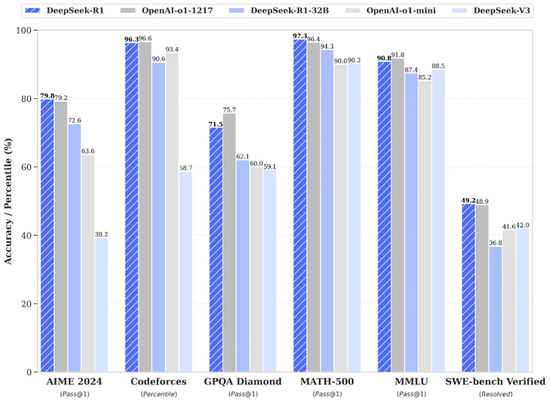
01-28 14:00...该公司正式发布推理大模型DeepSeek-R1。一经推出,DeepSeek-R1便凭借其物美价廉的特性在海外开发者社区中引发了轰动。作为一款开源模型,R1在数学、代码、自然语言推理等任务上的性能能够比肩OpenAIo1模型正式版,并采用MIT许可协议,支持免费商用、任意修改和衍生开发等。目前,在国外大模型排名榜Chat... 7
-
01-28 12:20...OpenAI前员工AndrewCarr称赞该论文充满惊人智慧,并将其训练设置应用于自己的模型。Anthropic联合创始人JackClark则表示,DeepSeek雇佣了一批高深莫测的奇才。梁文锋是位80后,来自广东湛江吴川。2002年,他以吴川市第一中学高考状元的成绩考上浙江大学电子信息工程专业,毕业后继续攻读研究生... 6
-
01-28 12:20...DeepSeek全称杭州深度求索人工智能基础技术研究有限公司,成立于2023年7月17日,专注于开发先进的大语言模型和技术。在硅谷,该公司被称作“来自东方的神秘力量”,也是网上热议的“杭州六小龙”之一。2024年底,DeepSeek发布了新一代大语言模型V3,并宣布开源。测试结果显示,该模型在多项评测中超越了一些主流开... 0
-
-
01-28 12:10...而DeepSeek-R1则被许多人视为OpenAI的o1等推理模型的强大竞争对手。DeepSeek之所以能以极低的成本训练出高性能的大模型,主要得益于其算法创新。该公司使用了一系列工程技巧优化了模型架构,如强化学习技术和多头潜在注意力机制,显著降低了算力成本。此外,DeepSeek还通过数据总结和分类提高了训练效率,实... 7
-
01-27 23:30...激活参数为370亿,在14.8万亿token上进行了预训练。V3在知识类任务上接近当前表现最好的Claude-3.5-Sonnet-1022,在代码能力上稍好于后者,并且在数学能力上领先其他开闭源模型。更重要的是,DeepSeek-V3的总训练成本仅为557.6万美元,完整训练消耗了278.8万个GPU小时,几乎是同等... 0
-
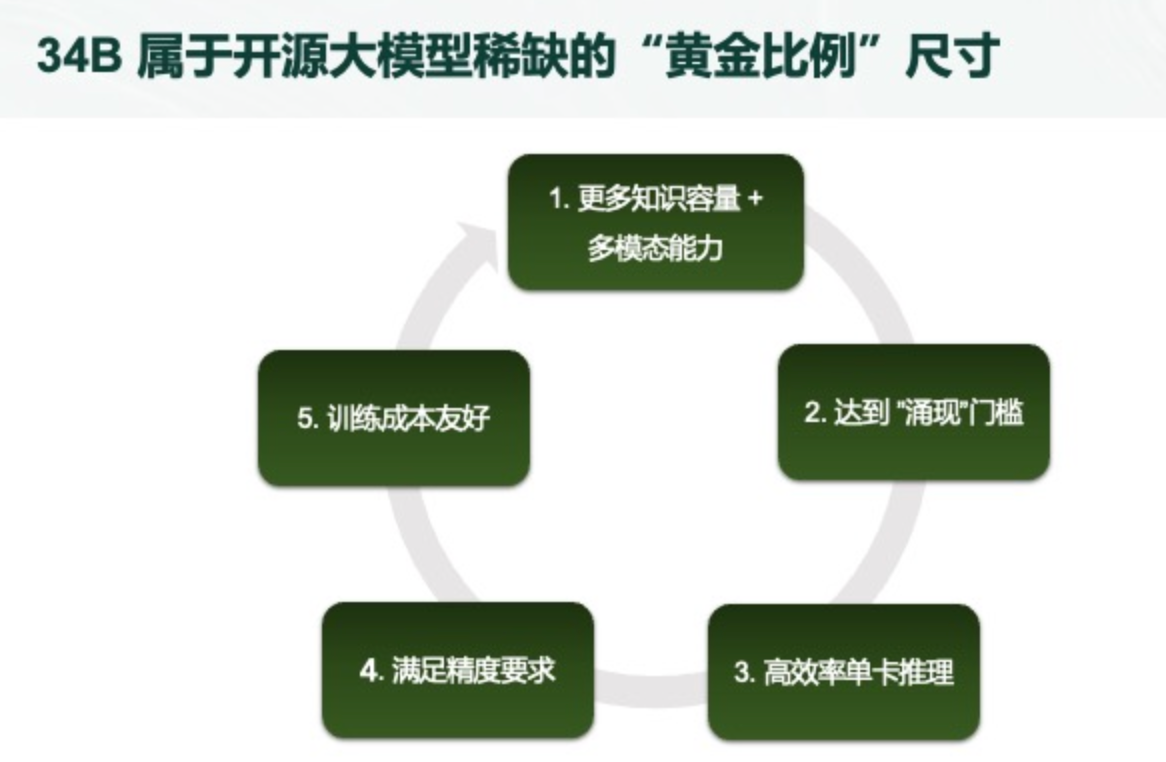
11-07 04:50...李开复认为开源模型的发布就是一个验证开源社区与开源方法论的尝试。HuggingFace作为AI领域的Github,提供大量开源模型与工具。根据HuggingFace英文开源社区平台和C-Eval中文评测的最新榜单,Yi-34B预训练模型取得多项SOTA国际最佳性能指标认可。此次零一万物开源发布的Yi系列模型,包含34B... 2
-
11-07 03:40...没有一个春天不会来临。”市场积极因素在多个领域持续涌现。宏观经济持续复苏、经济政策持续发力、市场底部特征越发明显、做多资金摩拳擦掌。多家公募基金公司、券商资管机构开启新一轮自购,用真金白银传递信心。前海开源基金自2022年9月以来已累计自购近5.8亿元。前海开源基金副总经理、权益投资决策委员会主席曲扬认为,当前是中国权... 2
-
-


-
本页Url:
-
2025-02-01-12:48 GMT . 添加到桌面浏览更方便.
-

