
2023-02-08 , 7433 , 104 , 202
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-7
人机接口:从In Context Learning到Instruct理解
一般我们经常提到的人和LLM的接口技术包括:zero shot prompting、few shot prompting、In Context Learning,以及Instruct。这些其实都是表达某个具体任务的描述方式。不过如果你看文献,会发现叫法比较乱。
其中Instruct 是ChatGPT的接口方式,就是说人以自然语言给出任务的描述,比如 “把这个句子从中文翻译成英文”,类似这种。zero shot prompting我理解其实就是现在的Instruct的早期叫法,以前大家习惯叫zero shot,现在很多改成叫Instruct。尽管是一个内涵,但是具体做法是两种做法。早期大家做zero shot prompting,实际上就是不知道怎么表达一个任务才好,于是就换不同的单词或者句子,反复在尝试好的任务表达方式,这种做法目前已经被证明是在拟合训练数据的分布,其实没啥意思。目前Instruct的做法则是给定命令表述语句,试图让LLM理解它。所以尽管表面都是任务的表述,但是思路是不同的。
而In Context Learning和few shot prompting意思类似,就是给LLM几个示例作为范本,然后让LLM解决新问题。我个人认为In Context Learning也可以理解为某项任务的描述,只是Instruct是一种抽象的描述方式,In Context Learning是一种例子示范的例子说明法。当然,鉴于目前这几个叫法用的有点乱,所以上述理解仅代表个人看法。
所以我们此处只对In Context Learning和Instruct进行介绍,不再提zero shot和few shot了。
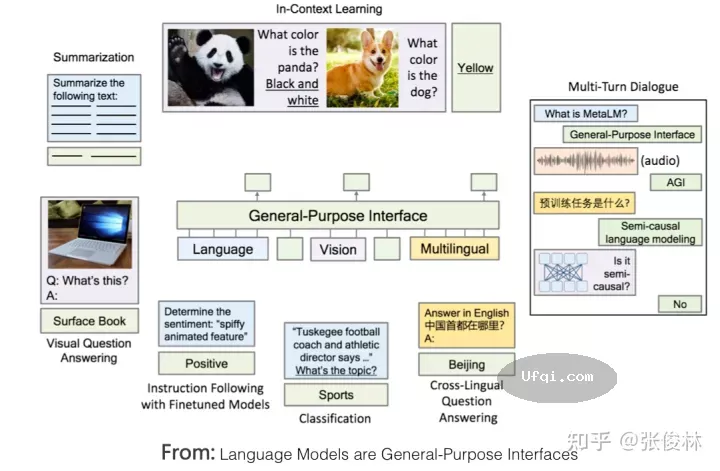
神秘的In Context Learning
如果你细想,会发现In Context Learning是个很神奇的技术。它神奇在哪里呢?神奇在你提供给LLM几个样本示例 <�1,�1>,<�2,�2>....<��,��> ,然后给它 ��+1 ,LLM竟然能够成功预测对应的 ��+1 。
听到这你会反问:这有什么神奇的呢? Fine-tuning不就是这样工作的吗?你要这么问的话,说明你对这个问题想得还不够深入。
Fine-tuning和In Context Learning表面看似都提供了一些例子给LLM,但两者有质的不同(参考上图示意):Fine-tuning拿这些例子当作训练数据,利用反向传播去修正LLM的模型参数,而修正模型参数这个动作,确实体现了LLM从这些例子学习的过程。但是,In Context Learning只是拿出例子让LLM看了一眼,并没有根据例子,用反向传播去修正LLM模型参数的动作,就要求它去预测新例子。既然没有修正模型参数,这意味着貌似LLM并未经历一个学习过程,如果没有经历学习过程,那它为何能够做到仅看一眼,就能预测对新例子呢?
这正是In Context Learning的神奇之处。这是否让你想起了一句歌词: “只是因为在人群中多看了你一眼 再也没能忘掉你容颜”,而这首歌名叫“传奇”。你说传奇不传奇?

看似In Context Learning没从例子里学习知识,实际上,难道LLM通过一种奇怪的方式去学习?还是说,它确实也没学啥?关于这个问题的答案,目前仍是未解之谜。现有一些研究各有各的说法,五花八门,很难判断哪个讲述的是事实的真相,甚至有些研究结论还相互矛盾。这里提供几个目前的说法,至于谁对谁错,只能你自己把握了。当然,我认为追求这个神奇现象背后的真相,是一个好的研究课题。
试图证明In Context Learning没有从例子中学习的工作是 “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”。它发现了:在提供给LLM的样本示例 <��,��> 中, �� 是否 �� 对应的正确答案,其实并不重要,如果我们把正确答案 �� 替换成随机的另外一个答案 �� ,这并不影响In Context Learning的效果。这起码说明了一点:In Context Learning并没有提供给LLM那个从 � 映射到 � 的映射函数信息: �=�(�) ,否则的话你乱换正确标签,肯定会扰乱这个 �=�(�) 映射函数。
也就是说,In Context Learning并未学习这个输入空间到输出空间的映射过程。
真正对In Context Learning影响比较大的是: � 和 � 的分布,也就是输入文本 � 的分布和候选答案 � 有哪些,如果你改变这两个分布,比如把 � 替换成候选答案之外的内容,则In Context Learning效果急剧下降。
总之,这个工作证明了In Context Learning并未学习映射函数,但是输入和输出的分布很重要,这两个不能乱改。
有些工作认为LLM还是从给出的示例学习了这个映射函数 �=�(�) ,不过是种隐式地学习。比如 “What learning algorithm is in-context learning? Investigations with linear models”认为Transformer能够隐式地从示例中学习 � 到 � 的映射过程,它的激活函数中包含了一些简单映射函数,而LLM通过示例能够激发对应的那一个。而“Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers”这篇文章则将ICL看作是一种隐式的Fine-tuning。
总而言之,目前这还是一个未解之谜。
神奇的Instruct理解
我们可以把Instruct当作一种方便人类理解的任务表述,在这个前提下,目前关于Instruct的研究可以分成两种:偏学术研究的Instruct,以及关于人类真实需求描述的Instruct。
我们先来看第一种:偏学术研究的Instruct。它的核心研究主题是多任务场景下,LLM模型对Instruct理解的泛化能力。如上图中FLAN模型所示,就是说有很多NLP任务,对于每个任务,研究人员构造一个或者多个Prompt模版作为任务的Instruct,然后用训练例子对LLM模型进行微调,让LLM以同时学习多个任务。
训练好模型后,给LLM模型一个它没见过的全新任务的Instruct,然后让LLM 解决zero shot任务,从任务解决得是否足够好,来判断LLM模型是否有对Instruct理解的泛化能力。
如果归纳下目前的研究结论(可参考 “Scaling Instruction-Fine-tuned Language Models”/“Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks”),能够有效增加LLM模型Instruct泛化能力的因素包括:增加多任务的任务数量、增加LLM模型大小、提供CoT Prompting, 以及增加任务的多样性。如果采取任意一项措施,都可以增加LLM模型的Instruct理解能力。
第二种是人类真实需求下的Instruct,这类研究以InstructGPT和ChatGPT为代表。这类工作也是基于多任务的,但是和偏向学术研究类工作最大的不同,在于它是面向人类用户真实需求的。为什么这么说呢?因为它们用于LLM多任务训练的任务描述Prompt,是从大量用户提交的真实请求中抽样而来的,而不是固定好研究任务的范围,然后让研究人员来写任务描述prompt。这里所谓的 “真实需求”,体现在两个方面:首先,因为是从用户提交的任务描述里随机抽取的,所以涵盖的任务类型更多样化,也更符合用户的真实需求;其次,某个任务的prompt描述,是用户提交的,体现了一般用户在表达任务需求时会怎么说,而不是你认为用户会怎么说。
很明显,这类工作改出来的LLM模型,用户体验会更好。
UfqiLong
InstructGPT论文里,也拿这种方法和FLAN那种Instruct based方法做了比较。首先在GPT3上用FLAN提到的任务、数据以及Prompt模版进行微调,来在GPT 3上复现FLAN方法,然后和InstructGPT进行比较,因为InstructGPT的基础模型也是GPT3,所以只有数据和方法的差别,两者可比,结果发现FLAN方法的效果,距离InstructGPT有很大的差距。那么背后的原因是什么呢?论文分析数据后认为,FLAN方法涉及到的任务领域相对少,是InstructGPT涉及领域的子集,所以效果不好。也就是说,FLAN论文里涉及到的任务和用户真实需求是不符的,而这导致在真实场景下效果不够好。而这对我们的启示是:从用户数据中收集真实需求,这事情是很重要的。
In Context Learning和Instruct的联系
如果我们假设In Context Learning是用一些例子来具象地表达任务命令,Instruct是一种更符合人类习惯的抽象任务描述。那么,一个很自然的问题是:它们之间有什么联系吗?比如,我们是否能够提供给LLM完成某个任务的若干具体示例,让LLM找出其对应的自然语言描述的Instruct命令?
目前有零星的工作在探索这个问题,我认为这个方向是很有研究价值的。先说答案,答案是:Yes,LLM Can。 “Large Language Models Are Human-Level Prompt Engineers”是做这个方向很有趣的工作,如上图所示,对于某项任务,给LLM一些示例,让LLM自动生成能够描述这项任务的自然语言命令,然后它再用LLM生成的任务描述去测试任务效果。
它使用的基础模型是GPT 3和InstructGPT,经过这项技术加持后,LLM生成的Instruct的效果相比未采用这项技术的GPT 3 以及InstuctGPT来说,指标有极大地提升,而且在一些任务上超过人类的表现。
这说明了:具象的任务示例和任务的自然语言描述之间,有种神秘的内在联系。至于这种联系到底是什么?我们目前对此还一无所知。

🔗 连载目录
6. 试用美国OpenAI的ChatGPT有感:一个新时代正拉开序幕-2
7. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要
8. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-2
9. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-3
 10. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4
10. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4
11. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-5
12. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-6
🔴 13. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-7
 14. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-8
14. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-8
15. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-9
16. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-10
17. 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11
19. 美国微软内部人士谈谈OpenAi的强人工智能ChatGPT
20. 美国OpenAi公司的人工智能聊天机器人ChatGPT能取代多少程序员?
21 22 2324. 百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
25🤖 智能推荐
2010年的房地产调控,我们收获了什么?写在房价暴涨前-40
人的行为 Human Action-21:第3章 經濟學以及對理知的反叛
福尔摩斯探案集-中-35:失去的世界-13:十一、我当了一次英雄
时间的朋友跨年演讲全文-2024年-6:一种置身事内的领导力-3
🔥 相关精选
