
... 2023-04-28 04:10 .. 根据新的欧盟立法草案文本,人工智能(AI)服务提供商将被要求披露用于构建系统的版权材料。
草案文本写道,生成人工智能模型的开发者必须公布他们所使用版权材料的“足够详细的汇总”。
这意味着,当出版商和内容创作者的作品成为AI生成内容的材料时,他们可以依据这项拟议的法案条例获得利润。
这也是自聊天机器人ChatGPT公布以来,欧盟方面最关注的商业问题之一。
据了解,开发商在训练大语言模型时需要摄取网络上数十亿的文本、图像、视频、音乐、代码等,才能使模型导出营销文案、新的图像或新的歌曲。
此前,代表14万多名作家和表演者的42家德国协会和工会敦促欧盟加强人工智能规则草案,他们指出ChatGPT对他们的版权构成了威胁,并在致欧盟委员会、欧洲理事会和欧盟立法者的一封信中表达了他们的担忧。
信中称,“未经授权使用受保护的训练材料,其不透明的处理,以及可预见的人工智能输出替代来源,引 .. UfqiNews ↓
15
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11
取经之路:复刻ChatGPT时要注意些什么
如果希望能复刻类似ChatGPT这种效果令人惊艳的LLM模型,综合目前的各种研究结论,在做技术选型时需要重点权衡如下问题:
首先,在预训练模式上,我们有三种选择:GPT这种自回归语言模型,Bert这种双向语言模型,以及T5这种混合模式(Encoder-Decoder架构,在Encoder采取双向语言模型,Decoder采取自回归语言模型,所以是一种混合结构,但其本质仍属于Bert模式).
我们应选择GPT这种自回归语言模型,其原因在本文范式转换部分有做分析.
目前看,国内LLM在做这方面技术选型的时候,貌似很多都走了Bert双向语言模型或T5混合语言模型的技术路线,很可能方向走偏了.
第二,强大的推理能力是让用户认可LLM的重要心理基础,而如果希望LLM能够具备强大的推理能力,根据目前经验,最好在做预训练的时候,要引入大量代码和文本一起进行LLM训练.
至于其中的道理,在本文前面相关部分有对应分析.
第三,如果希望模型参数规模不要那么巨大,但又希望效果仍然足够好,此时有两个技术选项可做配置:要么增强高质量数据收集、挖掘、清理等方面的工作,意思是我模型参数可以是ChatGPT/GPT 4的一半,但是要想达到类似的效果,那么高质量训练数据的数量就需要是ChatGPT/GPT 4模型的一倍(Chinchilla的路子);另外一个可以有效减小模型规模的路线是采取文本检索(Retrieval based)模型+LLM的路线,这样也可以在效果相当的前提下,极大减少LLM模型的参数规模.
这两个技术选型不互斥,反而是互补的,也即是说,可以同时采取这两个技术,在模型规模相对比较小的前提下,达到超级大模型类似的效果.
... 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11 ⟶
2023中国经济传媒大会媒体论坛文字实录-13
(中国传媒大学教授)沈浩:
非常高兴受传媒茶话会的邀请参加这样一个会议,今天同步在杭州也在举办世界人工智能大会,是每年一届,规模很大的会议.
同步我们有四个国家重点实验室,在媒体领域,第一个是人民日报的,主要在认知科学领域;第二个是中央电视台,主要是在5G、4K/8K高清传输上;
第三个是新华社,主要是在科技赋能媒体上.
对于我们这样一个媒体融合与传播国家重点实验室,主要有四个定位,第一个是未来媒体的服务模式,未来媒体的形态,以及媒体信息的智能处理技术.
今年我们也增加了一个很重要的国际传播,当然对于今天的话题,关于GPT,或者是语言大模型,当前最重要的GPT的应用,主要还是在安全性和可控性上.
对于GPT来讲,它是自然语言处理,早期自然语言处理NLP主要是两个方向,一个是自然语言的理解NLU,一个是自然语言的生成NLG.
有人说自然语言是人工智能的皇冠,今天大数据语言的模型诞生以后,真正的可能这个皇冠就坐稳了.
但今天所有的大数据,包括今天在杭州举办的世界人工智能大会,把所有的焦点、热点都关注在了AIGC这个领域,所以GPT这个概念,其实已经是一个颠覆性的、革命性的,所以首先我们应该拥抱这样的GPT.
实际上GPT的本身含义是生成预训练的迁移模型,所以我们可以在这个模型上做很多深度的加工,无论是广度还是深度.
一个模型包括了几个方面的意思,第一,这个模型是参数的多少,反映了这个模型的大小.
第二是这个模型的语料所具有的特征,当然也涉及到模型的应用场景,比如它可以在web上,在浏览器上就可以实行.
第二个是可以在API,这是一个重点的,因为API有可能就穿透了我们的网络,穿透了可能的安全性.
当然了,大部分今天我们看到的基于GPT的应用,由于自身的限制,或者 ... 2023中国经济传媒大会媒体论坛文字实录-13 ⟶

本页Url
🤖 智能推荐
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11 30
美国OpenAI的ChatGPT预示人类思维探索的极大进步-2 30
AI换脸成女星带货,化解生成式人工智能风险当用足法律工具 26
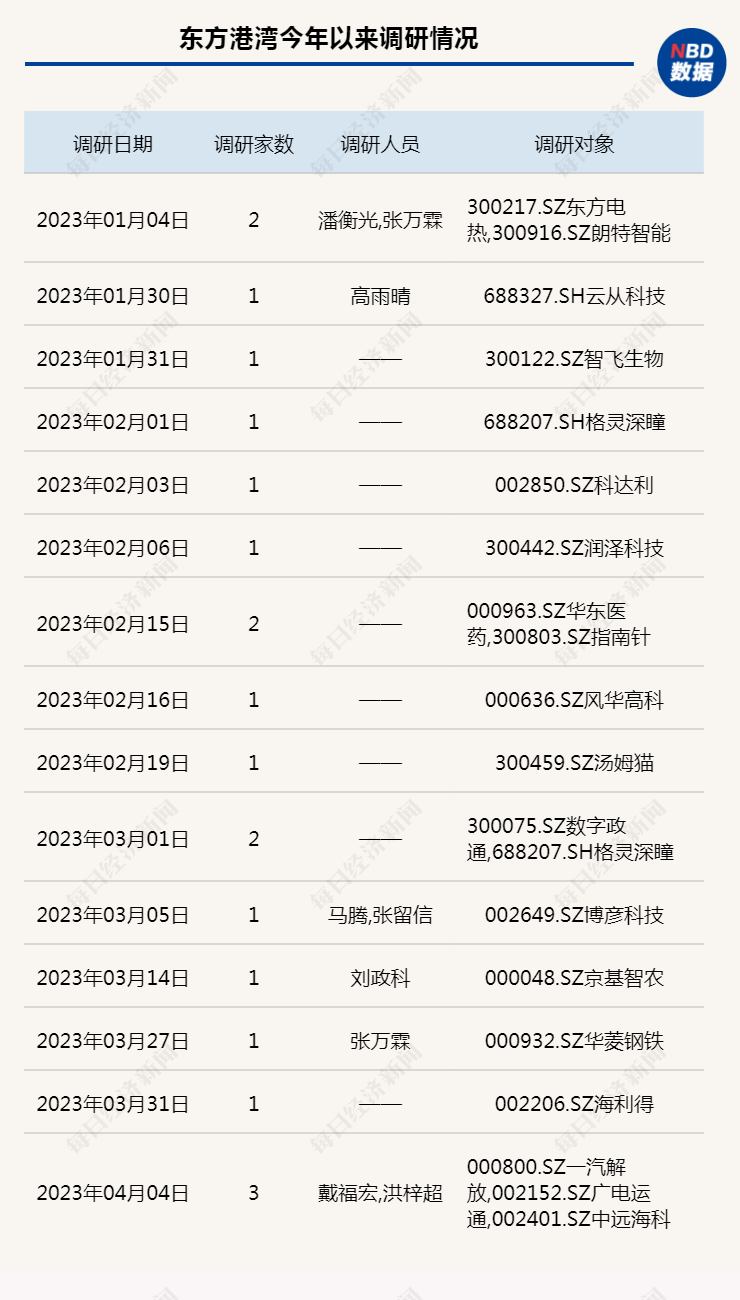 热榜!嘴上喊“有风险” 旗下基金却重仓“AI大牛股” 但斌回应了
21
热榜!嘴上喊“有风险” 旗下基金却重仓“AI大牛股” 但斌回应了
21
ChatGPT掀起技术狂潮:顶流之下,看人工智能喜与忧 19
🔥 相关精选
 AI换脸明星直播带货教程热传:平台如何管控 有何侵权风险
9
AI换脸明星直播带货教程热传:平台如何管控 有何侵权风险
9
利空突袭!2倍大牛股突发减持公告,560亿龙头也“撇清“!欧盟还将出台“限制“法案,最火概念要熄火? 3
(两会访谈)全国人大代表谈Sora:用数字技术拉紧人工智能的“缰绳” 1
