
... 2023-04-19 03:00 .. 包括自然语言处理大模型、视觉大模型、跨模态大模型、生物计算大模型,行业大模型以及配套的工具平台等,其中蕴含了大量我们自主创新的并已在大规模产业应用中得到验证的技术.”
作为“文心”大家族的一员,运用人工智能算法,文心一言已经学习吸收了超过万亿知识,具备了强大的学习能力,但王海峰强调:“刚满月的文心一言还在废寝忘食地学习,在一日千里地进步,真实的用户反馈是一言学习的珍贵素材,会帮助它加速进步.”
人工智能技术已经越来越快、越来越多地参与到社会生产及人们的生活,以生成式人工智能为主要特征的大语言模型在解决实际问题时的出色表现使其成为全球关注焦点,却也加重了人们的焦虑和担忧。
针对人们普遍担忧的工作岗位将被人工智能取代这一问题,王海峰指出,随着人工智能技术广泛应用,一些岗位有可能被人工智能应用替代,但不会带来严重的失业问题,纵观过去200多年的历史,任何一次科技革命和产 .. UfqiNews ↓
2
[编按: 转载于 新浪网/李德林, 2023-04-17. ]
中国人工智能AI大语言模型LLM的道场
熙熙攘攘这命运的道场,曾燃起希望烧一片空旷.
现在,人工智能的大模型犹如修行的道场,在2023年的春天百花争鸣.
如果手上没有一本《山海经》,都已经看不懂科技巨头们在人工智能领域的群雄逐鹿了.
AI的赛道上已经拥挤不堪,谁能成为最后的赢家?
(美国OpenAI公司的聊天人工智能机器人)ChatGPT一出,科技界、学术界一片沸腾,比尔盖茨、扎克伯格、马斯克、巴菲特都卷入了人工智能的狂风暴雨之中.
砸了千亿,在AI道路上摸爬滚打10年的百度,第一个站出来发布了对标chatGPT的产品文心一言.
百度的挺身而出,点燃了整个中国的AI大模型激情.
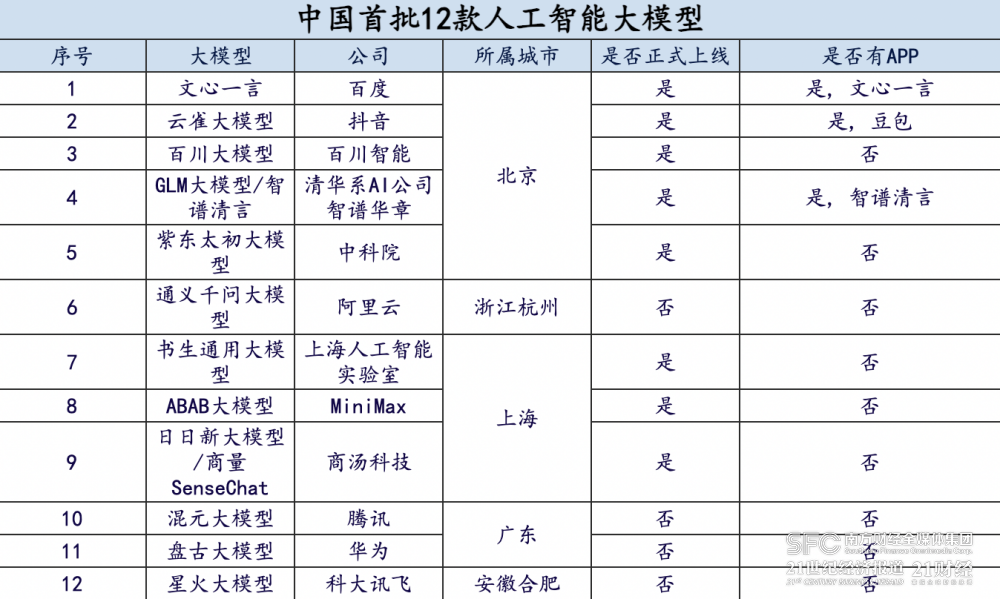
华为的盘古、360的智脑、商汤的日日新、阿里的通义千问、京东的言犀、腾讯的混元、字节的自研、网易的玉言、澜舟科技的孟子、达观数据的曹植、中科院的紫东太初、科大讯飞的1+N认知、浪潮的源1.0、昆仑万维的天工3.5等大模型纷纷登场.
美团的联合创始人王慧文、搜狗创始人王小川,重出江湖,亲自下注,带动一批资金,再战大模型.
现在的中国人工智能领域,已经从天地未分前的混沌元气,到盘古开天辟地,从孟子的金玉良言,到才高八斗的七步成诗,如果你读书不从《山海经》开始,没有个五千年的文化沉淀,你已经无法看明白科技领域的雄心壮志.
对于科技界的一众巨 ... 中国人工智能AI大语言模型LLM的道场 ⟶
03-19 00:32 , 8056 , 186 ..
[编按: 转载于 腾讯微信/ 阳志平 心智工具箱, 2023-03-18.
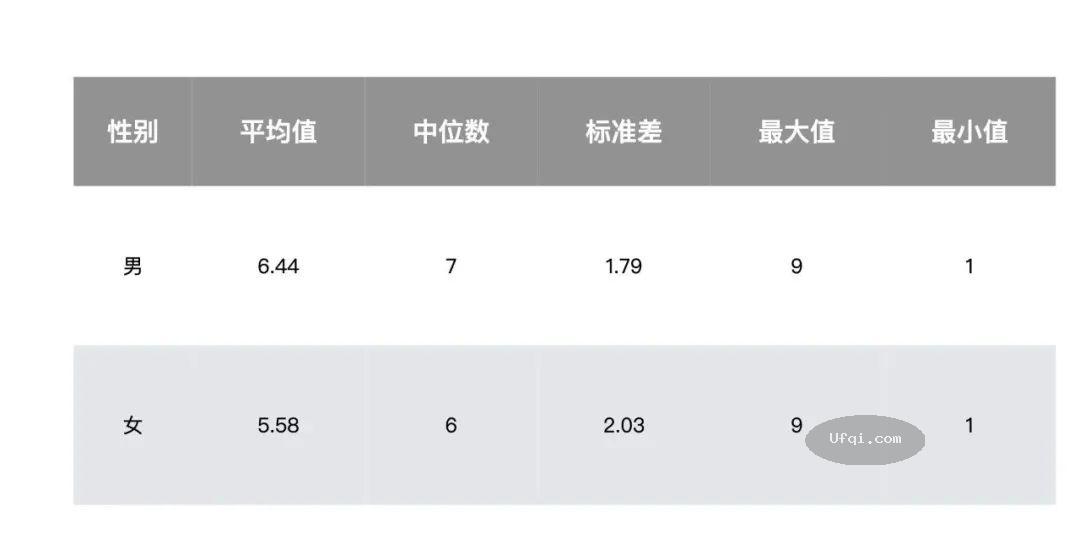
文心一言的理性思维能力距离 GPT-4 差多少?我们第一时间测试了一下.
]
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
背景
如果将大语言模型想象成一个人,那么,通过对它的人格、智商、理性与社会情绪能力进行心理测量,是不是可以清晰地描绘出大语言模型的心智成熟程度.
这就是新兴的人工智能心理测量学.
只是,在人工智能心理测量学中,我们不再测查人类,而是测查大语言模型以及各类机器人.
在 GPT-4 发布之后,我们第一时间测查了它在理性思维能力测验上的表现,并将其与 GPT-3.5 的结果、253 位受过高等教育的人进行对比.
结果发现,GPT-4 实现了大跃迁,达到了一个超越人类的水准.
详情参见:理性思维超越人类?GPT-4真正大杀八方的是这项能力
测试流程
在百度文心一言发布之后,我们第一时间获得邀请码,选择了在前文中测试 GPT-3.5 与 GPT-4 一致的题目、流程.
详细说明请参考前文.
这里不再啰嗦.
简而言之,我们挑选了认知科学家用来评定人类理性思维的四类经典测试任务:语义错觉类任务;认知反射类任务;证伪选择类任务;心智程序类任务.
四类任务总计 26 道题目.
在测试之前,我们已经预估文心一言的表现会不如 GPT-4,但最终实际测试结果还是令人大跌眼镜,可能与百度开发团队的认知有关系.
在下文中,我会略作分析.
需要提醒的是,本报告仅仅是一个早期工作,并不完善.
测试流程有无数可以改善之处.
结论未来随时可能被修正、被推翻.
各位读者请理解.
现在,让我们来详细看看测试结果.
分项测试结果 ... 百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少? ⟶

本页Url
🤖 智能推荐
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
27
数智赋能经济新业态 23
人工智能下个爆点出现?“自动驾驶版ChatGPT“重磅来袭,这家车企直接受益或迎自己的iPhone时刻 23
人工智能会导致人类灭亡吗?专家称更担心虚假信息和操纵用户 22
🔥 相关精选
 如何对标ChatGPT?专家:打造普适模型,助力形成新业态
16
如何对标ChatGPT?专家:打造普适模型,助力形成新业态
16
度小满许冬亮接受麦肯锡专访 大模型有望降低中小银行应用AI技术门槛 15
如何对标ChatGPT?专家:打造普适模型,助力形成新业态
15

 百度袁佛玉:文心一言将改变云计算游戏规则,申请企业超10万
4
百度袁佛玉:文心一言将改变云计算游戏规则,申请企业超10万
4
OpenAI再爆火,专家解析:Sora并不会让现实不复存在 3

文心一言与GPT 2
