Ooops, Data read error for 4257152, Try new one ( 读取异常, 请尝试搜索关键词 ) ....

... 2024-04-17 07:50 .. 大模型能够记忆、理解的文本长度越长,用户描述就能更加趋近准确。
大模型解决复杂问题、给出优质反馈的可能性也就越高、潜在的应用场景就越广泛。
生物相关专业在读研究生林栩向「市界」表示:3月下旬,他经过同学的推荐开始尝试用Kimi阅读英文文献,后来甚至让Kimi协助自己整理和填充论文提纲等,效果惊人:“粗略估计能节省我50%的时间精力吧”。
而AI从业者Amanda早在去年10月Kimi小范围内测时,就成为了首批种子用户,她对Kimi的走红早有心理预期。
她分享道:我愿意在任何场合大肆赞扬Kimi好用且实用。
无数个林栩和Amanda的深度使用和自发传播,让Kimi的系统流量持续高增。
Kimi的长文本背后,也意味着对于技术和算力的强大挑战。
AI研究者洛林向「市界」举了个例子:“如果我想让大模型写个长篇小说,它支持的上下文容量是首先要面临的问题。
我要把积累的大量素材、人物框 .. UfqiNews ↓ 0
03-15 04:49 , 8009 , 179 ..
[编按: 转载于 新浪网/财经头条/新智元, 2023-03-15. GPT-4王者加冕!读图做题性能炸天,凭自己就能考上斯坦福.
]
美国OpenAI的ChatGPT-4发布:多模态图文混合交互
【新智元导读】Open AI的GPT-4在万众瞩目中闪亮登场,多模态功能太炸裂,简直要闪瞎人类的双眼.
李飞飞高徒、斯坦福博士Jim Fan表示,GPT4凭借如此强大的推理能力,已经可以自己考上斯坦福了!
果然,能打败昨天的Open AI的,只有今天的Open AI.
(2023年03月)刚刚,Open AI震撼发布了大型多模态模型GPT-4,支持图像和文本的输入,并生成文本结果.
号称史上最先进的AI系统!
GPT-4不仅有了眼睛可以看懂图片,而且在各大考试包括GRE几乎取得了满分成绩,横扫各种benchmark,性能指标爆棚.
Open AI 花了 6 个月的时间使用对抗性测试程序和 ChatGPT 的经验教训对 GPT-4 进行迭代调整 ,从而在真实性、可控性等方面取得了有史以来最好的结果.
大家都还记得,2月初时微软和谷歌鏖战三天,2月8日微软发布ChatGPT版必应时,说法是必应「基于类ChatGPT技术」.
今天,谜底终于解开了——它背后的大模型,就是GPT-4!
图灵奖三巨头之一Geoffrey Hinton对此赞叹不已,「毛虫吸取了营养之后,就会化茧为蝶.
而人类提取了数十亿个理解的金块,GPT-4,就是人类的蝴蝶.
」
 顺便提一句,ChatGPT Pl ... 美国OpenAI的ChatGPT-4发布:多模态图文混合交互 ⟶
顺便提一句,ChatGPT Pl ... 美国OpenAI的ChatGPT-4发布:多模态图文混合交互 ⟶ 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11
取经之路:复刻ChatGPT时要注意些什么
如果希望能复刻类似ChatGPT这种效果令人惊艳的LLM模型,综合目前的各种研究结论,在做技术选型时需要重点权衡如下问题:
首先,在预训练模式上,我们有三种选择:GPT这种自回归语言模型,Bert这种双向语言模型,以及T5这种混合模式(Encoder-Decoder架构,在Encoder采取双向语言模型,Decoder采取自回归语言模型,所以是一种混合结构,但其本质仍属于Bert模式).
我们应选择GPT这种自回归语言模型,其原因在本文范式转换部分有做分析.
目前看,国内LLM在做这方面技术选型的时候,貌似很多都走了Bert双向语言模型或T5混合语言模型的技术路线,很可能方向走偏了.
第二,强大的推理能力是让用户认可LLM的重要心理基础,而如果希望LLM能够具备强大的推理能力,根据目前经验,最好在做预训练的时候,要引入大量代码和文本一起进行LLM训练.
至于其中的道理,在本文前面相关部分有对应分析.
第三,如果希望模型参数规模不要那么巨大,但又希望效果仍然足够好,此时有两个技术选项可做配置:要么增强高质量数据收集、挖掘、清理等方面的工作,意思是我模型参数可以是ChatGPT/GPT 4的一半,但是要想达到类似的效果,那么高质量训练数据的数量就需要是ChatGPT/GPT 4模型的一倍(Chinchilla的路子);另外一个可以有效减小模型规模的路线是采取文本检索(Retrieval based)模型+LLM的路线,这样也可以在效果相当的前提下,极大减少LLM模型的参数规模.
这两个技术选型不互斥,反而是互补的,也即是说,可以同时采取这两个技术,在模型规模相对比较小的前提下,达到超级大模型类似的效果.
... 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11 ⟶

本页Url
🤖 智能推荐
美国OpenAI的ChatGPT-4发布:多模态图文混合交互 23
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11 54
OpenAI 机器人炸裂登场!ChatGPT 终于有身体了,能说会看还能做家务 12
谷歌发布AI语言模型PaLM 2 挑战OpenAI的GPT 8
🔥 相关精选
2024全国两会/AI新世代/国产AI双线出击 比肩ChatGPT 追赶Sora 1
复旦等发布AnyGPT:任意模态输入输出,图像、音乐、文本、语音都支持 1
新模型Sora爆火 OpenAI估值或达800亿美元 行业除了震撼还有两大隐患 1
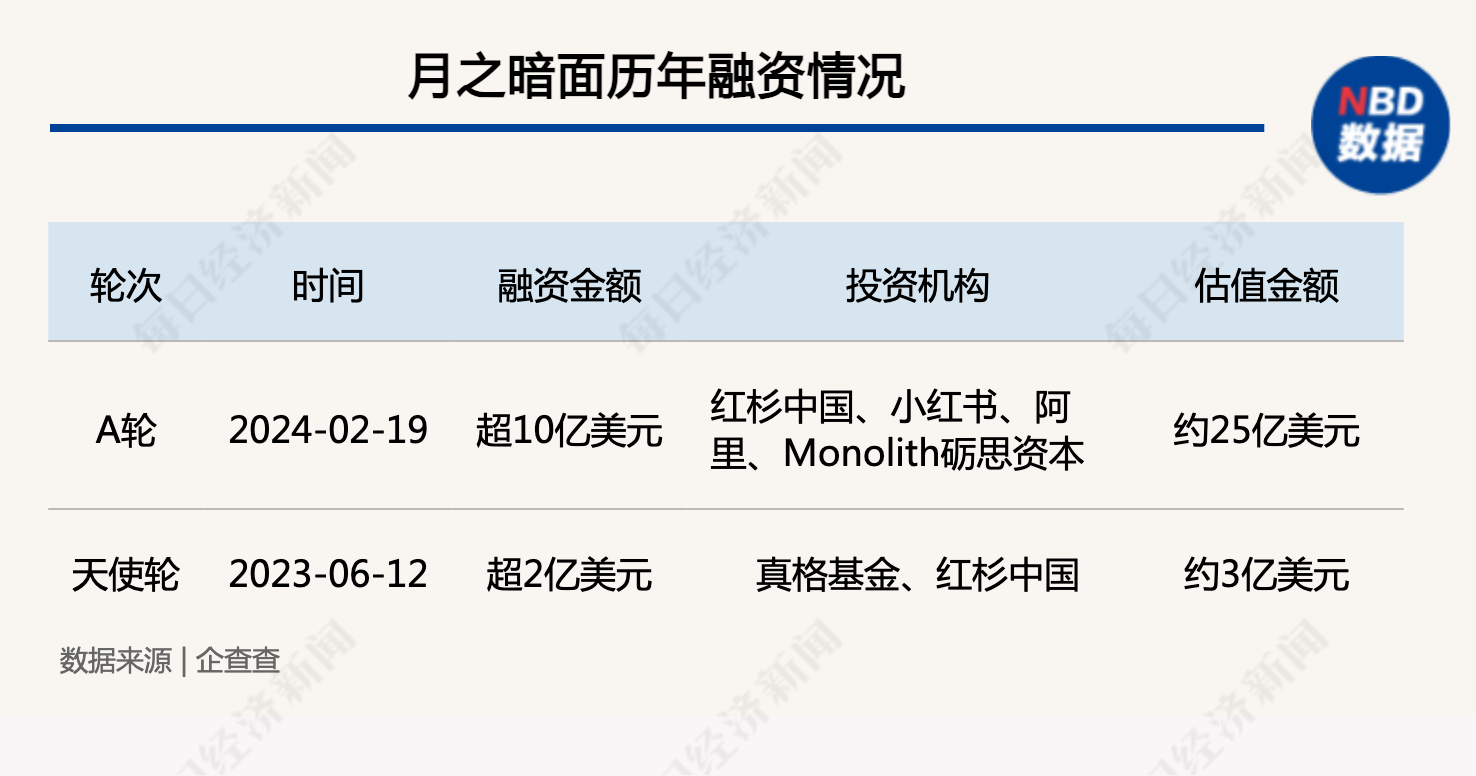 创始人套现数千万美金?前金沙江创投合伙人加入?月之暗面回应 0
创始人套现数千万美金?前金沙江创投合伙人加入?月之暗面回应 0
