
2021-04-14 , 2602 , 101 , 153
几周前我写了篇关于并发的文章(透过 rust 探索系统的本原:并发篇),从使用者的角度介绍了常用的处理并发的工具:Mutex / RwLock / Channel,以及 async/await。今天我们讲讲这些并发手段背后的原语。这些原语,大家在操作系统课程时大多学过,但如果不是做一些底层的开发,估计大家都不记得了。
今天,我们就来简单聊聊这些基础的并发原语,了解它们的差异,明白它们使用的场景,对撰写高性能的并发应用有很大的帮助。
有同学可能会问:我一个写 web 的,需要 synchronize 的时候靠 db / message queue,再不济用 Redlock [1],了解这些玩意儿有啥用?嗯,有点道理。如果你的工作大部分是 CRUD,写一些和数据库打交道的 HTTP API,这些东西的确用处不大,也许你不是本文的读者。
但如果你想让自己的技能树稍微丰富一些,能做一些别人做不了的事情,能面对不同的场景设计出来更高效的系统,那么这篇文章也许值得一读。
今天我们讲的东西,可能会略微枯燥,略微难懂,我会尽量引入足够的扩展知识,把上下文讲清楚。我们重点讲解和深入几个概念:atomic,mutex,condvar 和 channel。
Atomic
Atomic 是所有并发原语的基础。在具体介绍 atomic 之前,我们先考虑一下,最基本的锁该如何实现。我们假设要用一把锁来保护某个数据结构的修改,使其在多线程环境下可以正常工作(独占或者互斥访问)。为了简便起见,我们在获取这把锁的时候,如果获取不到,就一直死循环,直到拿到锁为止:
struct Lock
3. 如今的编译器会最大程度优化生成的指令 —— 如果操作之间没有依赖关系,那么可能会生成乱序的机器码,比如:**3 被优化放在 **1 之前,从而破坏了这个 lock 的保证。
4. 即便编译器不做乱序处理,CPU 也会最大程度做指令的乱序执行,让流水线的效率最高。同样会发生 3 中的问题。
所以,我们实现的这个锁的行为是未定义的。可能大部分时间如你所愿,但随机出现奇奇怪怪的行为。一旦这样的事情发生,那么,bug 可能会以各种不同的面貌出现在系统的各个角落。而且,这样的 bug 几乎是无解的:它很难稳定复现,表现行为很不一致,甚至,只在某个 CPU 下出现。
为了解决这样的问题,我们必须在 CPU 层面做一些保证,让某些操作成为原子操作,其中最基础的保证是:可以通过一条指令读取某个内存地址,判断其值是否等于某个前置值,如果相等,将其修改为新的值。这就是 Compare-and-swap 操作,简称 CAS [3]。这个操作是操作系统的几乎所有并发原语的基石,它使得我们可以实现一个可以正常工作的锁。
对于上述的代码,我们可以把一开始的循环改成:
while self
.locked
.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed)
.is_error() {}
这句的意思是:如果 locked 当前的值是 false,那么就将其改成 true。整个这个操作在一条指令里完成,不会被其它线程打断或者修改;如果 locked 的当前值不是 false,那么就会返回错误,我们会在此不停 spin,直到前置条件得到满足。
这里,compare_exchange 是 Rust 提供的 CAS 操作,它会被编译成 CPU 的对应的 CAS 指令。
当这句执行成功后,locked 必然会被改变为 true,我们成功拿到了锁,而任何其他线程都会在这句话上 spin。
在释放锁的时候,我们相应地需要使用 atomic 的版本,而非直接赋值成 false:
self.locked.store(false, Ordering::Release);
当然,为了配合这样的改动,我们还需要把 locked 从 bool 改成 AtomicBool。在 Rust 里,std::sync::atomic 有大量的 atomic 数据结构,他们对应了各种基础结构。
通过使用 compare_exchange 我们可以规避上面 1 和 2 面临的问题,但对于 3 和 4,我们还需要一些额外处理。这就是这个函数里额外的两个和 Ordering 有关的奇怪的参数。
如果你查看 atomic 的文档[4],可以看到 Ordering 是一个 enum:
pub enum Ordering { Relaxed, Release, Acquire, AcqRel, SeqCst,}
文档里解释了几种 Ordering 的用途,我来稍稍扩展一下:
1. Relaxed:这是最宽松的规则,它对编译器和 CPU 不做任何限制,可以乱序
2. Release:当我们写入数据(上面的 store)的时候,如果用了 Release order,那么:
对于其它线程,如果它们使用了 Acquire 来读取这个 atomic 的数据, 那么它们看到的是修改后的结果。因为上文中我们在 compare_exchange 里使用了 Acquire 来读取,所以保证读到最新的值。
对于当前线程,任何读取或写入操作都不能被被乱序排在这个 store 之后。也就是说,在上文的例子里,CPU 或者编译器不能把 **3 挪到 **4 之后执行。
3. Acquire:当我们读取数据的时候,如果用了 Acquire order,那么:
对于其它线程,如果使用了 Release 来修改数据,那么,修改的值对当前线程可见。
对于当前线程,任何读取或者写入操作都不能被乱序排在这个读取之前。在上文的例子里,CPU 或者编译器不能把 **3 挪到 **1 之前执行。
4. AcqRel:Acquire 和 Release 的结合,同时拥有 Acquire 和 Release 的保证。这个一般用在 fetch_xxx 上,比如你要对一个 atomic 自增 1,你希望这个操作之前和之后的读取或写入操作不会被乱序,并且操作的结果对其它线程可见。
5. SeqCst:最严格的 ordering,除了 AcqRel 的保证外,它还保证所有线程看到的所有的 SeqCst 操作的顺序是一致的。
因为 CAS 和 ordering 都是系统级的操作,所以上面我描述的 Ordering 的用途在各种语言中都大同小异。对于 Rust 来说,它的 atomic 原语是继承于 C++,见[5]。如果读 Rust 的文档你感觉云里雾里,那么 C++ 的关于 ordering 的文档要清晰得多。
好,上述的锁的实现的完整代码如下:
pub fn with_lock
注意,我们在 while loop 里,又嵌入了一个 loop,这是因为 CAS 是个代价比较高的操作,它需要获得对应内存的独占访问(exclusive access),我们希望失败的时候只是简单读取 atomic 的状态,只有符合条件的时候再去做独占访问,进行 CAS。所以,看上去我们多做了一层循环,实际代码的效率更高。
以下是两个线程同步的过程,一开始 t1 拿到锁,t2 spin,之后 t1 释放锁,t2 进入到临界区执行:
通过上面的例子,相信你对 atomic 以及其背后的 CAS 有个初步的了解,如果你还想对 Rust 下使用 atomic 有更多更深入的了解,可以看 Jon Gjengset 最新一期 Crust of Rust: Atomics and Memory Ordering [6]。巧的是这周我计划写有关并发原语的文章,Jon 的视频就出来了,帮我进一步夯实了关于 atomic 的知识。
上文中,为了展示如何使用 atomic,我们制作了一个非常粗糙简单的 SpinLock [7]。SpinLock,顾名思义,就是线程通过 CPU 空转(spin,就像上文中的 while loop),来等待某个锁可用的一种锁。SpinLock 和 Mutex lock 最大的不同是,使用 SpinLock,线程在忙等(busy wait),而使用 Mutex lock,线程会在等待锁的时候被调度出去,等锁可用时再被被调度回来。

听上去 SpinLock 似乎效率很低,但这要具体看锁的临界区的大小。如果临界区要执行的代码很少,那么和 Mutex lock 带来的上下文切换(context switch)相比,SpinLock 是值得的。在 Linux Kernel 中,很多时候,我们只能使用 SpinLock。
Rust 的 spin-rs crate [8] 提供了 spinlock 的实现。
那么,atomic 除了做其它并发原语,还有什么作用?
我个人用的最多的是做各种 lock-free 的数据结构。比如,我们需要一个全局的 id 生成器。我们当然可以使用 uuid 这样的模块来生成唯一的 id,但如果我们同时需要这个 id 是有序的,那么 AtomicUsize 就是最好的选择。
你可以用 fetch_add 来增加这个 id,而 fetch_add 返回的结果就可以用于当前的 id。这样,我们不需要加锁,就得到了一个可以在多线程中安全使用的 id 生成器。
另外,atomic 还可以用于记录系统的各种 metrics。比如我做的一个简单的 in-memory Metrics 模块:
use std::{ collections::HashMap,
sync::atomic::{AtomicUsize, Ordering},};
// server statisticspub struct Metrics(HashMap<&'static str, AtomicUsize>);
impl Metrics {
pub fn new(names: &[&'static str]) -> Self {
let mut metrics: HashMap<&'static str, AtomicUsize> = HashMap::new();
for name in names.iter() {
metrics.insert(name, AtomicUsize::new(0)); }
Self(metrics) }
pub fn inc(&self, name: &'static str) {
if let Some(m) = self.0.get(name) {
m.fetch_add(1, Ordering::Relaxed); } }
pub fn add(&self, name: &'static str, val: usize) { if let Some(m) = self.0.get(name) { m.fetch_add(val, Ordering::Relaxed); } }
pub fn dec(&self, name: &'static str) {
if let Some(m) = self.0.get(name) {
m.fetch_sub(1, Ordering::Relaxed); } }
pub fn snapshot(&self) -> Vec<(&'static str, usize)> {
self.0
.iter()
.map(|(k, v)| (*k, v.load(Ordering::Relaxed)))
.collect() }}
它允许你初始化一个全局的 metrics 表,然后在程序的任何地方无锁地操作相应的 metrics:
lazy_static! {
pub(crate) static ref METRICS: Metrics = Metrics::new(&[
"topics", "clients", "peers", "broadcasts", "servers", "states", "subscribers" ]);}
Mutex
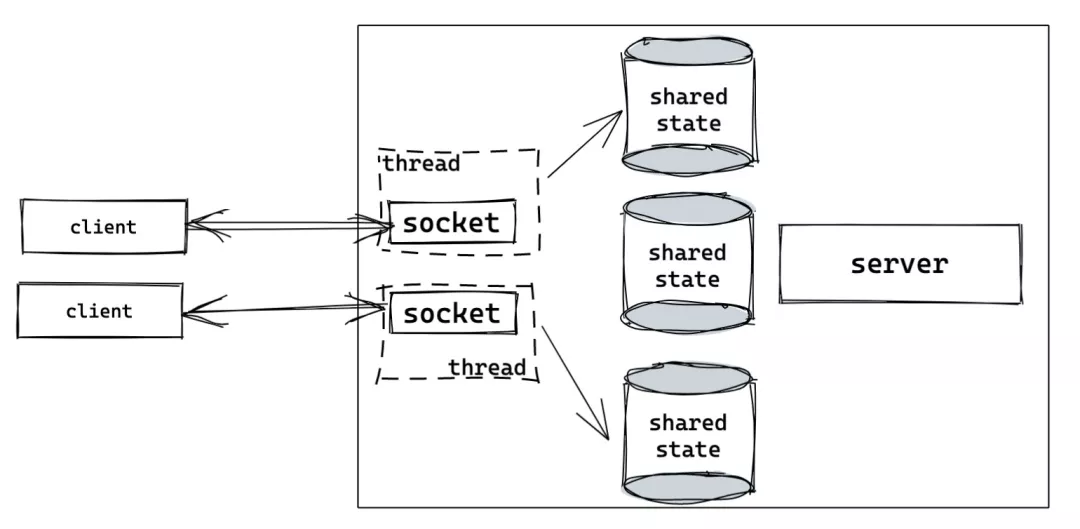
在并发处理中,一个核心的问题就是资源共享:软件系统如何控制多个线程对同一个共享资源的访问,使得每个线程可以在访问共享资源的时候独占或者说互斥访问(MUTual EXclusive access)?
我们知道,对于一个共享资源,如果所有线程只做读操作,那么无需互斥,大家随时可以访问,很多 immutable language(如 erlang/elixir)做了语言层面的只读保证,确保了并发环境下的无锁操作[9]。这牺牲了一些效率(常见的 list/hashmap 需要使用 immutable data structure),额外做了不少内存拷贝,换来并发控制下的简单轻灵。
然而一旦有任何一个或多个线程要修改共享资源,那么不但写者之间要互斥,读写之间也需要互斥。如果读写之间不互斥的话,那么读者轻则读到脏数据,重则读到已经被破坏的数据,导致 crash。比如读者读到链表里的一个节点,而写者恰巧把这个节点的内存释放,如果不做互斥访问,系统一定会崩溃。
用来解决这种读写互斥问题的一大基本工具就是 Mutex(RwLock 我们放下不表)。
上文中,我们制作的简单的 spinlock,可以看做是一个广义的 Mutex。然而,这种通过 spinlock 做互斥的实现方式有使用场景的限制:如果受保护的临界区太大,那么整体的性能会急剧下降, CPU 忙等,浪费资源还不干实事,不适合作为一种通用的处理方法。
更通用的解决方案是:当多个线程竞争同一个 Mutex 时,获得锁的线程得到临界区的访问,其它线程会被挂起,放入该 Mutex 上的一个等待队列。当获得锁的线程完成工作,退出临界区时,Mutex 会给等待队列发一个信号,把队列中第一个线程唤醒,于是这个线程可以进行后续的访问。整个过程如下:

我们前面也讲过,线程的上下文切换代价很大,所以频繁将线程挂起再唤醒,会降低整个系统的效率。所以很多 Mutex 具体的实现会将 spinlock(确切地说是 spin wait)和线程挂起结合使用:线程的 lock 请求如果拿不到会先尝试 spin 一会,然后再挂起添加到等待队列。Rust 下的 parking_lot [10] 就是这样实现的。
当然,这样实现会带来公平性的问题:如果新来的线程恰巧在 spin 过程中拿到了锁,而当前等待队列中还有其它线程在等待锁,那么等待的线程只能继续等待下去,这不符合 FIFO,不适合那些需要严格按先来后到排队的使用场景。为此,parking_lot 提供了 fair mutex。
Mutex 的实现依赖于 CPU 提供的 atomic。你可以把 Mutex 想象成一个粒度更大的 atomic,只不过这个 atomic 无法由 CPU 保证,而是通过软件算法来实现。
至于操作系统里另一个重要的概念信号量(semaphore ),你可以认为是 Mutex 更通用的表现形式。比如在新冠疫情下,图书馆要控制同时在馆内的人数,如果满了,其他人就必须排队,出来一个才能再进一个。这里,如果总人数限制为 1,就是 Mutex,如果 > 1,就是 semaphore。
大家可以想想可以怎么实现 semaphore。也可以想想这样的人数控制系统怎么用信号量实现(提示:Rust 下 tokio 提供了 tokio::sync::Semaphore)。
Condvar
Mutex 解决了并发环境下共享资源如何安全访问的问题,但它没有解决一个更高层次的问题:如果这种访问需要按照一定顺序进行,该怎么做?这个问题的典型的场景是生产者消费者模式:生产者生产出来内容后,需要有机制通知消费者可以消费。比如 socket 上有数据了,通知处理线程处理数据,处理完成之后,再通知 socket 收发的线程发送数据。
更复杂的场景如我之前文章《透过 rust 探索系统的本原:并发篇》:数据接收,通知数据写入,日志写满,通知 S3 upload。在这个例子里我使用了 channel 来完成,但 condvar 也适用:

在操作系统里,condvar 是一种状态:
等待(wait):线程在队列中等待,直到满足某个条件
通知(notify):当 condvar 的条件满足时,当前线程通知其他等待的线程可以被唤醒。通知可是是单个通知,也可以是多个通知,甚至广播(通知所有人)。
在实践中,Condvar 往往和 Mutex 一起使用:Mutex 用于保证条件的读写时互斥的,Condvar 用于控制线程的等待和唤醒。
我们通过实现 mpsc channel 来看看 condvar 是如何使用的。如果你用过 channel,你知道 channel 创建后可以一端写,一端读,其内部共享一个 ring buffer(在 Rust 里我们可以用 VecDequeue)。当 channel 里没有数据可读时,读者会挂起(block),而写者写入新的数据时,需要通知读者恢复运行。
这个过程,我们需要通过 Condvar 来实现。对于 mpsc channel 来说,channel 可以有多个写者,一个读者,这是最经典 channel。
首先我们定义读者,写者,以及 channel 函数本身:
pub struct Sender
对于写者,拿到锁之后可以往 queue 里面添加数据,添加完之后,要调用 notify_one 来唤醒可能挂起的读者(如果没有,notify_one 基本啥也不做):
impl
UfqiLong
<t></t>
<t></t>
<t></t>
<t></t>
<t></t>
<t></t>
<t></t>
<t></t>
<t></t>
注意在调用 wait 时,需要把当前拿住的锁交给 Condvar,Condvar 会将其释放,然后把读者加入等待队列,当有人 notify_one 时,队列中的读者会被唤醒,重新拿到锁,然后继续进行。
目前这个实现还有一个问题:如果写者退出了,没有人再写数据,在队列里的读者不会有人唤醒,所以我们还需要对 channel 所有的写者做一个计数 —— 自然的,你会想到使用 atomic 来完成,这就是为什么 Shared
在所有写者退出的时候,我们还需要唤醒在等待队列中的读者,所以我们要调用 notify_one 来做通知。注意 atomic fetch 得到的结果是改变前的值,所以这里上一次是 1 的话,这次一减,所有写者都没了,所以我们要在这个时候通知。
剩下的,都是一些边边角角的工作,比如读者退出后,写者在往 queue 里写的时候需要返回错误等等。
以上是一个很简单的 mpsc channel 的实现,里面需要做性能优化的地方还很多。如果你对 channel 的实现感兴趣,可以看 Rust 下 crossbeam channel [11] 或者 flume [12] 的实现。flume 没有使用 Condvar 来做 signal,而是使用 thread::park 和 thread::notify 自己写了一个简单的 SyncSignal。
希望通过这个例子,你能对 Condvar 的使用有更深刻的认识。如果我们需要在线程间通过一定的条件来进行同步,那么 Condvar 是一个不错的选择。此外,Condvar 还是一个非常不错的,在多个线程间广播的工具。
Channel
由于 golang 不遗余力的推广,channel 可能是最广为人知的并发手段。相对于 Mutex,channel 的抽象程度最高,接口最为直观,使用起来的心理负担也没那么大。使用 Mutex 时,你需要很小心地避免死锁,控制临界区的大小,防止一切可能发生的意外。
虽然在 Rust 里,我们可以「无畏并发」(Fearless concurrency)—— 当我们的代码编译通过,那么绝大多数并发问题都可以规避,但性能上的问题,逻辑上的死锁还需要开发者照料。channel 把锁封装在了队列写入和读取的小块区域内,然后把读者和写者完全分离,使得读者读取数据和写者写入数据,对开发者而言,除了潜在的上下文切换外,完全和锁无关,就像访问一个本地队列一样。所以,对于大部分并发问题,我们都可以用 channel 或者类似的思想来处理(比如 actor model)。
channel 在具体实现的时候,根据不同的使用场景,会选择不同的工具。上文中实现的一个简单的 mpsc channel,我们使用了 Mutex + Condvar + VecDeque,那么其它类型的 channel 呢?
我们大致捋一捋:
1. oneshot:这可能是最简单的 channel,写者就只发一次数据,而读者也只读一次。这种一次性的多个线程间的同步可以用 oneshot channel 完成。由于 oneshot 特殊的用途,实现的时候可以直接用 atomic swap 来完成。
2. rendezvous:很多时候,我们只需要通过 channel 来控制线程间的同步,并不需要发送数据。rendezvous channel 是 channel size 为 0 的一种特殊情况。这种情况下,我们用 Mutex + Condvar 实现就足够了。
rendezvous channel 其实就是 Mutex + Condvar 的一个包装,可以用 Condvar 代替。
3. bounded:bounded channel 有一个 queue,但 queue 有一个上限。一旦 queue 被写满了,写者也需要被挂起等待。上文中我们实现的是一个 unbounded mpsc channel,写者是可以无阻塞写的,而 bounded channel 写者有可能被阻塞。
当阻塞发生后,读者一旦读取数据,需要 notify_one 通知写者,唤醒某个写者使其能够继续写入。因此,我们可以用 Mutex + Condvar + VecDeque 来实现(大家感兴趣的话,可以在上文例子的基础上,将其修改为 bounded channel)。如果不用 Condvar,可以直接使用 thread::park + thread::notify 来完成(flume 的做法),如果不用 VecDeque,也可以使用双向链表或者其它的 ring buffer 的实现。
4. unbounded:queue 没有上限,如果写满了,就自动扩容。Rust 的很多数据结构如 Vec ,VecDeque 都是自动扩容的。unbounded 和 bounded 相比,除了不阻塞写者,其它实现都很类似。
所有这些 channel 类型,同步和异步的实现思路大同小异,主要的区别在于挂起/唤醒的对象。在同步的世界里,挂起/唤醒的对象是线程;而异步的世界里,是粒度很小的 task。
Mutex / Condvar 也是如此。
当我们做大部分复杂的系统设计时,channel 往往是最有力的武器,它除了可以让数据穿梭于各个线程,各个异步任务间,其接口还可以很优雅地跟 stream 适配。如果说我们在做整个后端的系统架构时,着眼的是我们有哪些服务,服务和服务之间如何通讯,数据如何流动,服务和服务间如何同步;那么在做某一个服务的架构时,着眼的是有哪些功能性的线程(异步任务),它们之间的接口是什么样子,数据是如何流动,如何同步。
在这里,channel 兼具接口,同步和数据流三种功能,所以我说是最有力的武器。
然而它不该是唯一的武器。我们面临的真实世界的并发问题是多样的,解决方案也应该是多样的,计算机科学家们在过去的几十年里不断探索,构建的一系列的并发原语,也说明了很难有一种银弹解决所有问题。就连 Mutex 本身,在实现中,还会根据不同的场景做不同的妥协(比如做 faireness 的妥协),因为这个世界就是这样,鱼与熊掌不可兼得,没有完美的解决方案,只有妥协出来的解决方案。
所以 channel 不是银弹,actor model 不是银弹,lock 不是银弹。一门好的编程语言可以提供大部分场景下的最佳实践(如 erlang/golang),但不该营造一种气氛,只有某个最佳实践才是唯一方案。很不幸的是,golang 对 channel 的过分宣传和痴迷使得很多程序员遇到问题就试图用 channel 解决,颇有一种拿着锤子到处找钉子的感觉。
相反,Rust 提供几乎你需要的所有解决方案,并且并不鼓吹他们的优劣,完全交由你按需选择。我在用 Rust 撰写多线程应用时,channel 是我的第一选择,但我还是会在合适的时候使用 Mutex,RwLock,Semaphore,Condvar,Atomic 等工具,而不是试图笨拙地用 channel 叠加 channel 来应对所有的场景。
贤者时刻
我们在学习某个知识时,我认为最好的方式是拿破仑式的战法:炮兵洗地,骑兵冲击,最后由步兵扫尾和巩固阵地。
比如对于 Mutex,我的炮兵是维基百科和有关 Mutex 的文献(Linux 的 Futex的介绍,LWN.net 相关的文档,Rust std 里关于 Mutex 的文档等),通过这些内容,高屋建瓴地理解概念本身;骑兵是源代码,比如 parking_lot(Rust std 关于 Mutex 的源码实际包装了 libc 的实现,所以直接看意义不太大)或者 libc 和 kernel 里对应的实现,通过阅读这些实现,你可以把理论和实际结合起来,并对业界的「最佳实践」有一个不错的理解;最后步兵是自己撰写一个 high level 的实现,比如上图,看着简单,实现起来还是有很多细节需要处理 —— 尤其是读代码的时候你仿佛读懂了,真要自己写的时候,发现不是那么一回事。
当你这么处理一轮之后,尤其层层递进,用步兵巩固阵地之后,这个知识就真真正正地成为你自己的学问,成为你的洞察力和判断力的一部分。之后,你就可以回答几乎任何与之相关的问题,即便这样的问题你没有学过,没有经历过,你也能找到一个分析框架,来解答这样的问题。
参考资料
[1] Redlock: https://redis.io/topics/distlock
[2] data 使用 UnsafeCell
[10] parking lot:https://github.com/Amanieu/parking_lot
[11] Flume: https://github.com/zesterer/flume
[12] Crossbeam channel:https://docs.rs/crossbeam-channel

🔗 连载目录

🤖 智能推荐

