
... 2023-05-24 08:40 .. 北京市有基础、有条件、也有责任加快打造人工智能技术创新策源地和产业发展高地。
“落实好中央关于人工智能发展的指示精神、加速发展通用人工智能技术并最大限度地转化为产业优势,是北京的使命,也是我们启动通用人工智能产业创新伙伴计划的初衷.”
北京市经信局副局长王磊表示。
据悉,“伙伴计划”的核心是聚集一批开放合作、协同发展的行业伙伴,通过有关部门邀请、企业自荐、行业组织推荐等渠道广泛征集。
伙伴共分为五类,即算力伙伴、数据伙伴、模型伙伴、应用伙伴和投资伙伴。
同时,为达成总体目标,“伙伴计划”还提出了八大任务作为支撑。
“伙伴计划”发布后,北京市将从资金支持、优化服务、加强推广、先行先试等六大维度着力,保障伙伴计划的顺利实施。
进入“伙伴计划”的成员单位,纳入市区两级重点企业服务名单;同时北京市将积极引入社会资本,鼓励设立通用人工智能产业基金,驱动科技创新、培育标杆企业、促进项 .. UfqiNews ↓ 11
[编按: 转载于 新浪网/李德林, 2023-04-17. ]
中国人工智能AI大语言模型LLM的道场
熙熙攘攘这命运的道场,曾燃起希望烧一片空旷.
现在,人工智能的大模型犹如修行的道场,在2023年的春天百花争鸣.
如果手上没有一本《山海经》,都已经看不懂科技巨头们在人工智能领域的群雄逐鹿了.
AI的赛道上已经拥挤不堪,谁能成为最后的赢家?
(美国OpenAI公司的聊天人工智能机器人)ChatGPT一出,科技界、学术界一片沸腾,比尔盖茨、扎克伯格、马斯克、巴菲特都卷入了人工智能的狂风暴雨之中.
砸了千亿,在AI道路上摸爬滚打10年的百度,第一个站出来发布了对标chatGPT的产品文心一言.
百度的挺身而出,点燃了整个中国的AI大模型激情.
华为的盘古、360的智脑、商汤的日日新、阿里的通义千问、京东的言犀、腾讯的混元、字节的自研、网易的玉言、澜舟科技的孟子、达观数据的曹植、中科院的紫东太初、科大讯飞的1+N认知、浪潮的源1.0、昆仑万维的天工3.5等大模型纷纷登场.
美团的联合创始人王慧文、搜狗创始人王小川,重出江湖,亲自下注,带动一批资金,再战大模型.
现在的中国人工智能领域,已经从天地未分前的混沌元气,到盘古开天辟地,从孟子的金玉良言,到才高八斗的七步成诗,如果你读书不从《山海经》开始,没有个五千年的文化沉淀,你已经无法看明白科技领域的雄心壮志.
对于科技界的一众巨 ... 中国人工智能AI大语言模型LLM的道场 ⟶
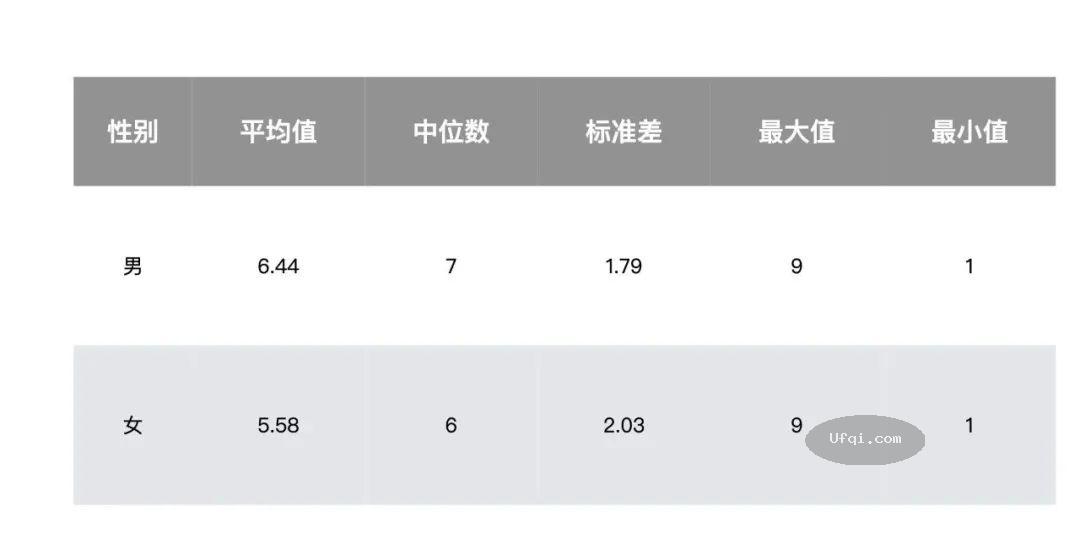
03-19 00:32 , 8056 , 185 ..
[编按: 转载于 腾讯微信/ 阳志平 心智工具箱, 2023-03-18.
文心一言的理性思维能力距离 GPT-4 差多少?我们第一时间测试了一下.
]
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
背景
如果将大语言模型想象成一个人,那么,通过对它的人格、智商、理性与社会情绪能力进行心理测量,是不是可以清晰地描绘出大语言模型的心智成熟程度.
这就是新兴的人工智能心理测量学.
只是,在人工智能心理测量学中,我们不再测查人类,而是测查大语言模型以及各类机器人.
在 GPT-4 发布之后,我们第一时间测查了它在理性思维能力测验上的表现,并将其与 GPT-3.5 的结果、253 位受过高等教育的人进行对比.
结果发现,GPT-4 实现了大跃迁,达到了一个超越人类的水准.
详情参见:理性思维超越人类?GPT-4真正大杀八方的是这项能力
测试流程
在百度文心一言发布之后,我们第一时间获得邀请码,选择了在前文中测试 GPT-3.5 与 GPT-4 一致的题目、流程.
详细说明请参考前文.
这里不再啰嗦.
简而言之,我们挑选了认知科学家用来评定人类理性思维的四类经典测试任务:语义错觉类任务;认知反射类任务;证伪选择类任务;心智程序类任务.
四类任务总计 26 道题目.
在测试之前,我们已经预估文心一言的表现会不如 GPT-4,但最终实际测试结果还是令人大跌眼镜,可能与百度开发团队的认知有关系.
在下文中,我会略作分析.
需要提醒的是,本报告仅仅是一个早期工作,并不完善.
测试流程有无数可以改善之处.
结论未来随时可能被修正、被推翻.
各位读者请理解.
现在,让我们来详细看看测试结果.
分项测试结果 ... 百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少? ⟶

本页Url
🤖 智能推荐
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少? 12
有关人工智能Artificial Intelligence AI的若干认识问题 30
中小企业计量伙伴计划出台 21
 亚信科技成为阿里云通义千问计划首批伙伴 携手共建通信行业大模型 16
亚信科技成为阿里云通义千问计划首批伙伴 携手共建通信行业大模型 16
🔥 相关精选
AI应用加速落地 A股产业链龙头衔枚疾进丨AI矩阵深观察② 2
北京打造大模型应用标杆 全国首个政务服务大模型场景需求发布 2
中国经济向前“进”丨小镇里的“大模型” 这里有100万台电脑的算力→ 0
