
... 2024-04-24 14:20 .. 提高材料利用率,甚至优化制造工艺和压缩新产品的验证周期。
而在软件方面,通常一家车企的开发团队以往凭借人工编写代码,可能一年只能写数千万行,而借助AI大模型,不仅可以更快提升效率,也能实现快速自动生成代码。
由此可见,随着AI大模型的不断成熟和应用的加速,不仅将给予软件代码有关的体系带来重构,也会带来整个零部件设计体系的变革。
例如,通过分析大量的车辆运行数据和充电数据,零部件企业可以优化电池管理系统和充电策略,用于提高电池的性能和寿命。
此外,大模型还可以帮助企业设计更高效的电驱动系统和能量回收系统,从而提高新能源汽车的续航里程和能源利用效率。
“预装AI大模型的操作系统,将实现智能驾驶、智能座舱以及整个中央计算和智能互联的合一,具有自学习、自进化和自成长能力.”
北方大数据与人工智能研究院研究员曾文翔向记者表示,AI大型模型在汽车设计与研发领域发挥着重要作用,可以通 .. UfqiNews ↓ 0
10-10 09:28 , 191 , 257 ..
[编按:理解计算系列由 腾讯/微信 SIGAI特邀作者:twinlj77, 最早发布于 2018-06-20,全文深入浅出,相当好的科普文章,对计算科学/人工智能初级生有帮助.
]
导言计算的概念看似简单却又十分宽泛,它实际上是计算机学科永远不变的核心内容,就算现在所谓的人工智能,在我看来也不过是一种计算或计算结果的应用.
本文将从简单的例子出发,逐步推广到目前人工智能的前沿研究领域,阐述我理解的计算的概念,希望借此培养大家的计算式思维方式,我们将看到这种思维方式是可以上升到一种行为方式的.
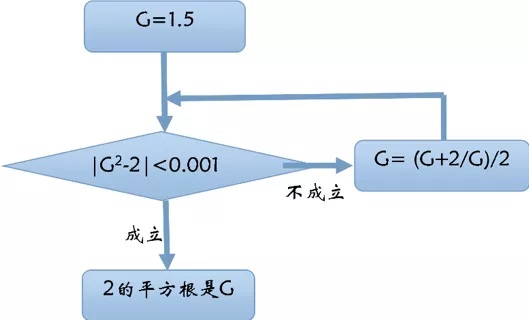
什么是计算?维基百科中,计算(Calculation) 是将一个或多个输入,利用称之为变量的东 ... 理解计算:从根号2到AlphaGo ——第1季 从根号谈起 ⟶
03-19 00:32 , 8056 , 185 ..
[编按: 转载于 腾讯微信/ 阳志平 心智工具箱, 2023-03-18.
文心一言的理性思维能力距离 GPT-4 差多少?我们第一时间测试了一下.
]
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
背景
如果将大语言模型想象成一个人,那么,通过对它的人格、智商、理性与社会情绪能力进行心理测量,是不是可以清晰地描绘出大语言模型的心智成熟程度.
这就是新兴的人工智能心理测量学.
只是,在人工智能心理测量学中,我们不再测查人类,而是测查大语言模型以及各类机器人.
在 GPT-4 发布之后,我们第一时间测查了它在理性思维能力测验上的表现,并将其与 GPT-3.5 的结果、253 位受过高等教育的人进行对比.
结果发现,GPT-4 实现了大跃迁,达到了一个超越人类的水准.
详情参见:理性思维超越人类?GPT-4真正大杀八方的是这项能力
测试流程
在百度文心一言发布之后,我们第一时间获得邀请码,选择了在前文中测试 GPT-3.5 与 GPT-4 一致的题目、流程.
详细说明请参考前文.
这里不再啰嗦.
简而言之,我们挑选了认知科学家用来评定人类理性思维的四类经典测试任务:语义错觉类任务;认知反射类任务;证伪选择类任务;心智程序类任务.
四类任务总计 26 道题目.
在测试之前,我们已经预估文心一言的表现会不如 GPT-4,但最终实际测试结果还是令人大跌眼镜,可能与百度开发团队的认知有关系.
在下文中,我会略作分析.
需要提醒的是,本报告仅仅是一个早期工作,并不完善.
测试流程有无数可以改善之处.
结论未来随时可能被修正、被推翻.
各位读者请理解.
现在,让我们来详细看看测试结果.
分项测试结果 ... 百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少? ⟶

本页Url
🤖 智能推荐
理解计算:从根号2到AlphaGo ——第1季 从根号谈起 45
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少? 52
 2023重庆车展丨全新ES6和全新ES8首次在重庆车展亮相 24
2023重庆车展丨全新ES6和全新ES8首次在重庆车展亮相 24



智驾新物种小鹏G6全球首发 小鹏汽车全系车型登陆上海车展 16

🔥 相关精选

6G将更好服务千行百业 10

从电驱到智能座舱全面覆盖, 小米汽车五大自研核心技术正式披露 3

 D级智能电动行政旗舰 蔚来ET9携四大核心技术亮相并开启预订 2
D级智能电动行政旗舰 蔚来ET9携四大核心技术亮相并开启预订 2

纯电旗舰MEGA剑指50万最好 理想全面进入“双能时代“ 2
