
... 2024-02-27 03:10 .. 360集团创始人周鸿祎则把宗庆后看作“前辈”“邻家大叔”,并因为看过一本介绍娃哈哈营销案例的书而产生醍醐灌顶的感觉。
宗庆后逝世后,中新经纬采访了多位与他有过接触的企业家及相关人士,他们通过点滴小事来追忆这位知名企业家的生平过往。
企业家悼念周鸿祎:一位朴素的“邻家大叔”2月22日,有媒体报道称宗庆后正在入院治疗。
当日,娃哈哈集团就公告称,宗庆后确因身体原因正在医院接受治疗,并称情况稳定。
22日,均瑶集团副董事长兼总裁王均豪在微博上说:“祝早日康复!又一位第一代企业家(出现)健康问题,还好(宗)馥莉已接班多年。
他只以事业为重,也没安排时间欣赏祖国大好河山,建议过没用,希望更多第一代企业家能劳逸结合,安排安享晚年……”但谁也没想到,仅仅三天后的25日10时30分,宗庆后因病逝世,生命定格在79岁。
王均豪随后在微博上称:“一路走好.”
对于如何评价宗庆后,王均豪在微信 .. UfqiNews ↓
1
02-08 06:09 , 7430 , 163 ..
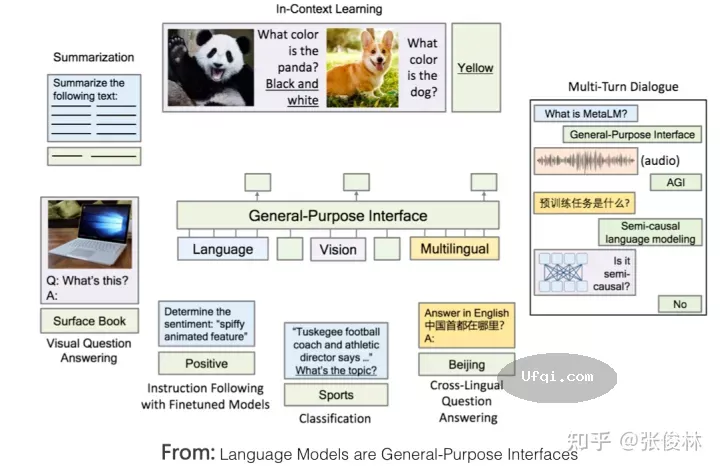
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4 影响一:让LLM适配人的新型交互接口
在理想LLM的背景下,我们再来看(美国OpenAI公司的)ChatGPT,能更好理解它的技术贡献.
ChatGPT应该是目前所有的现有技术里,最接近理想LLM的技术方法.
如果归纳下ChatGPT最突出特点的话,我会用下面八个字: “能力强大,善解人意”.
“能力强大”这一点,我相信应该主要归功于ChatGPT所依托的基础LLM GPT3.5.
因为ChatGPT 尽管加入了人工标注数据,但是量级只有数万,这个规模的数据量,和训练GPT 3.5模型使用的几千亿token级别的数据量相比,包含的世界知识(数据中包含的事实与常识)可谓沧海一粟,几可忽略,基本不会对增强GPT 3.5的基础能力发挥什么作用.
所以它的强大功能,应该主要来自于隐藏在背后的GPT 3.5.
GPT 3.5对标理想LLM模型中的那个巨无霸模型.
那么,ChatGPT向GPT 3.5模型注入新知识了吗?应该是注入了,这些知识就包含在几万人工标注数据里,不过注入的不是世界知识,而是人类偏好知识.
所谓 “人类偏好”,包含几方面的含义:首先,是人类表达一个任务的习惯说法.
比如,人习惯说:“把下面句子从中文翻译成英文”,以此表达一个“机器翻译”的需求,但是LLM又不是人,它怎么会理解这句话到底是什么意思呢?你得想办法让LLM理解这句命令的含义,并正确执行.
所以,ChatGPT通过人工标注数据,向GPT 3.5注入了这类知识,方便LLM理解人的命令,这是它“善解人意”的关键.
其次,对于什么是好的回答,什么是不好的回答,人类有自己的标准,例如比较详细的回答是好的,带有歧视内容的回答是不好的,诸如此类.
这是人类自身对回答质量好坏的偏好.
人通过Reward Model反馈给LLM的数据里,包含这类 ... 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4 ⟶
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11
取经之路:复刻ChatGPT时要注意些什么
如果希望能复刻类似ChatGPT这种效果令人惊艳的LLM模型,综合目前的各种研究结论,在做技术选型时需要重点权衡如下问题:
首先,在预训练模式上,我们有三种选择:GPT这种自回归语言模型,Bert这种双向语言模型,以及T5这种混合模式(Encoder-Decoder架构,在Encoder采取双向语言模型,Decoder采取自回归语言模型,所以是一种混合结构,但其本质仍属于Bert模式).
我们应选择GPT这种自回归语言模型,其原因在本文范式转换部分有做分析.
目前看,国内LLM在做这方面技术选型的时候,貌似很多都走了Bert双向语言模型或T5混合语言模型的技术路线,很可能方向走偏了.
第二,强大的推理能力是让用户认可LLM的重要心理基础,而如果希望LLM能够具备强大的推理能力,根据目前经验,最好在做预训练的时候,要引入大量代码和文本一起进行LLM训练.
至于其中的道理,在本文前面相关部分有对应分析.
第三,如果希望模型参数规模不要那么巨大,但又希望效果仍然足够好,此时有两个技术选项可做配置:要么增强高质量数据收集、挖掘、清理等方面的工作,意思是我模型参数可以是ChatGPT/GPT 4的一半,但是要想达到类似的效果,那么高质量训练数据的数量就需要是ChatGPT/GPT 4模型的一倍(Chinchilla的路子);另外一个可以有效减小模型规模的路线是采取文本检索(Retrieval based)模型+LLM的路线,这样也可以在效果相当的前提下,极大减少LLM模型的参数规模.
这两个技术选型不互斥,反而是互补的,也即是说,可以同时采取这两个技术,在模型规模相对比较小的前提下,达到超级大模型类似的效果.
... 迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11 ⟶

本页Url
🤖 智能推荐
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-4
53
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-11 45
迈向通用人工智能AGI之路:大型语言模型LLM技术精要-2 13

十六届德州市委全面深化改革委员会第五次会议暨省重点督导考核改革任务专题调度会议召开 18
增长15%!20条重点产业链铸就宿迁工业经济“信心”所在 11
🔥 相关精选
王钧:全力推进“三抓三促”行动走深走实 为加快全面转型高质量发展提供金昌市林业和草原局狠抓各项重点任务落实 10
全国重点海洋高校科研成果推介大会召开 央视网以创新模式助推海洋经济高质量发展 8
国务院办公厅关于印发第十次全国深化“放管服”改革电视电话会议重点任务分工方案的通知 5
1个目标!13项重点任务!4项保障措施!部省合力共建湖南现代职教体系新模式 3
 1个目标!13项重点任务!4项保障措施!部省合力共建湖南现代职教体系新模式
3
1个目标!13项重点任务!4项保障措施!部省合力共建湖南现代职教体系新模式
3
城厢区明确重点任务细化工作措施 推动农村建设品质提升“加速跑” 1
