
... 2024-04-19 22:40 .. 而生命共同体理念则强调了各国人民命运相连、休戚与共的实际处境,哪个国家都不可能独善其身,任何单边主义的行径都是在损害人类作为地球生命一员的整体利益。
在人类面临的生态危机挑战面前,倡导国际社会携手同行、共建地球生命共同体成为不二选择。
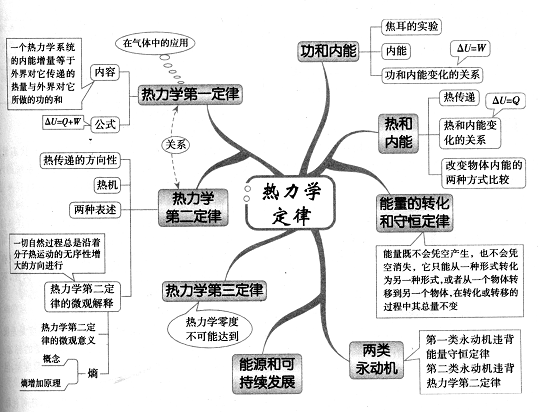
生态文明建设的内在要求。
良好生态环境是最普惠的民生福祉。
党的十九届六中全会通过的《中共中央关于党的百年奋斗重大成就和历史经验的决议》以十个明确系统概括了习近平新时代中国特色社会主义思想的核心内容,明确了中国特色社会主义事业总体布局是经济建设、政治建设、文化建设、社会建设、生态文明建设五位一体。
让人民生活更美好是我党执政为民的初心使命,生命共同体理念有力地指导了我国环境工作,围绕环境治理,党中央、国务院对水、土、大气污染防治工作做了全面部署,从影响群众生活最明显的事情做起,下大力气解决突出问题,改革体制机制。
当前,我国生态环境质量明 .. UfqiNews ↓ 0
02-14 11:01 , 460 , 217 ..
时光呼啸,2019年正迎面而来,我们与你又一次如约相见.
这是我们与你不变的约定,这是我们与你不变的仪式.
生命需要一种仪式感,给约定加上些许情怀与重量.
我们衷心地祝福你,新年快乐! 我们正在从改革开放四十年积累的基业再出发,心是笃定的.
但回望跌宕起伏的2018年,也有许多的不容易.
英国在试水“硬脱欧”,美国对各主要贸易伙伴挥起了大棒;行走在灰黑地带的P2P大面积爆雷,伪劣疫苗引爆众怒自取其咎;一些著名人物像燃尽的恒星一样独自带走了他们的时代,而公交车上发生的事件则告诉我们,大家同在一辆疾驰的车上,谁也不是旁观者,谁也无法置身事外.
是的,生活常常不容易.
当你告别象牙塔走向职场,却发现期望与现实之间落差巨大的时候;当你披星戴月驾驶大卡 ... 南方周末新年献词2019——每一个这样的你都是英雄 ⟶
03-19 00:32 , 8056 , 185 ..
[编按: 转载于 腾讯微信/ 阳志平 心智工具箱, 2023-03-18.
文心一言的理性思维能力距离 GPT-4 差多少?我们第一时间测试了一下.
]
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少?
背景
如果将大语言模型想象成一个人,那么,通过对它的人格、智商、理性与社会情绪能力进行心理测量,是不是可以清晰地描绘出大语言模型的心智成熟程度.
这就是新兴的人工智能心理测量学.
只是,在人工智能心理测量学中,我们不再测查人类,而是测查大语言模型以及各类机器人.
在 GPT-4 发布之后,我们第一时间测查了它在理性思维能力测验上的表现,并将其与 GPT-3.5 的结果、253 位受过高等教育的人进行对比.
结果发现,GPT-4 实现了大跃迁,达到了一个超越人类的水准.
详情参见:理性思维超越人类?GPT-4真正大杀八方的是这项能力
测试流程
在百度文心一言发布之后,我们第一时间获得邀请码,选择了在前文中测试 GPT-3.5 与 GPT-4 一致的题目、流程.
详细说明请参考前文.
这里不再啰嗦.
简而言之,我们挑选了认知科学家用来评定人类理性思维的四类经典测试任务:语义错觉类任务;认知反射类任务;证伪选择类任务;心智程序类任务.
四类任务总计 26 道题目.
在测试之前,我们已经预估文心一言的表现会不如 GPT-4,但最终实际测试结果还是令人大跌眼镜,可能与百度开发团队的认知有关系.
在下文中,我会略作分析.
需要提醒的是,本报告仅仅是一个早期工作,并不完善.
测试流程有无数可以改善之处.
结论未来随时可能被修正、被推翻.
各位读者请理解.
现在,让我们来详细看看测试结果.
分项测试结果 ... 百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少? ⟶

本页Url
🤖 智能推荐
百度公司的人工智能文心一言的理性思维能力距离美国OpenAI公司GPT-4差多少? 52

新思想引领新征程丨我国走出一条中国特色生物多样性保护之路 为共建地球生命共同体提供中国方案、中国经验 18
共同构建地球生命共同体 16

新思想引领新征程丨我国走出一条中国特色生物多样性保护之路 为共建地球生命共同体提供中国方案、中国经验 10
🔥 相关精选
78.为什么要像保护眼睛一样保护生态环境,像对待生命一样对待生态环境? 4

 倪岳峰主持召开河北省生态文明建设领导小组暨生态环境保护委员会会议 3
倪岳峰主持召开河北省生态文明建设领导小组暨生态环境保护委员会会议 3
生态保护让“绿水青山”铺满贵州大地|2023年“贵州生态日”系列评论一 3
2023年深入学习贯彻习近平生态文明思想研讨会在长沙举行 2
